版本: hanlp 2.0.0a37
tokenizer = hanlp.load(‘CTB6_CONVSEG’)
tagger = hanlp.load(‘CTB5_POS_RNN’)


以上1.7.x分词正常

版本: hanlp 2.0.0a37
tokenizer = hanlp.load(‘CTB6_CONVSEG’)
tagger = hanlp.load(‘CTB5_POS_RNN’)
以上1.7.x分词正常
欢迎反馈,反馈时请附上模型名称。我猜这是PKU模型,通常人民日报是不可能出现“性交”这种词语的,可以预见对这类词语支持较差。过些天会像1.x那样,发布一个亿级large语料库上的cws模型。
tokenizer = hanlp.load(‘CTB6_CONVSEG’)
tagger = hanlp.load(‘CTB5_POS_RNN’)
期待新模型😄

连环画、连环计 不能正确分词


卡拉OK 未被识别为一个词。
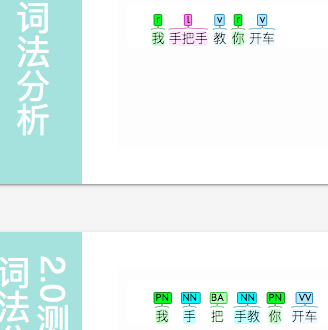
手把手 分词不正确。
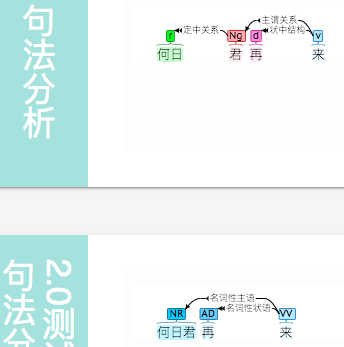
何日君再来

从上到下
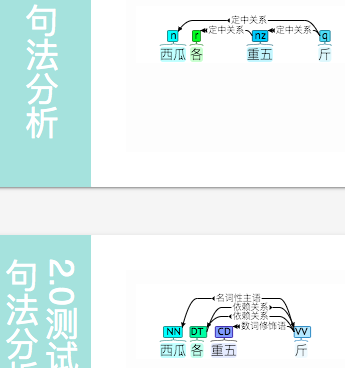
各重三斤、各重两斤、各重四斤 没错。 各重五斤 出错。


第多少、第若干 出错

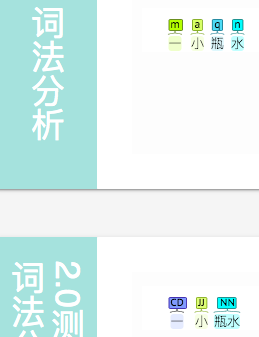
一小瓶水、两大车货
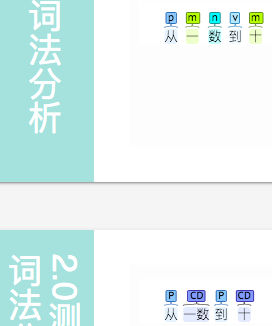
从一 数到 十
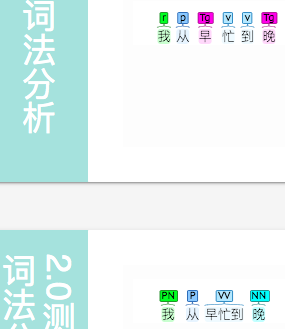
我从 早忙到 晚

购买毛巾 被 92条
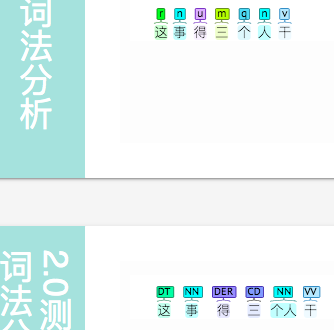
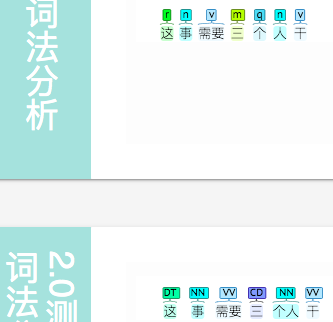

这事需要 三 个人 干, 个 人 应 分开
另外,这事  三个人干 , 意思同 “需要”,不应标记为 DER
三个人干 , 意思同 “需要”,不应标记为 DER
看上去这版模型很喜欢双字词,正在调新的模型。

马是
现代汉语确实也喜欢用双音节词。

颁布 法律
还是应分为两个词
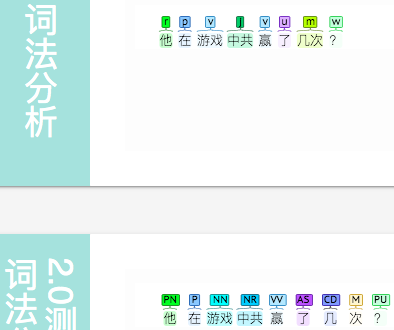
\color{blue}{游戏} \color{red}{中} \color{red}{共} \color{green}{赢} \color{yellow}{了}
“中”“共” 应分开
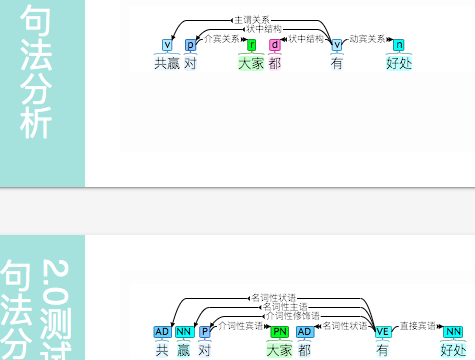
\color{red}{共赢}
“共赢” 应连起来
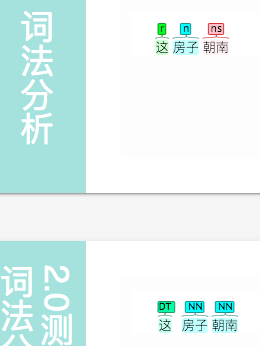
\color{red}{朝} \color{blue}{南}
应该分开