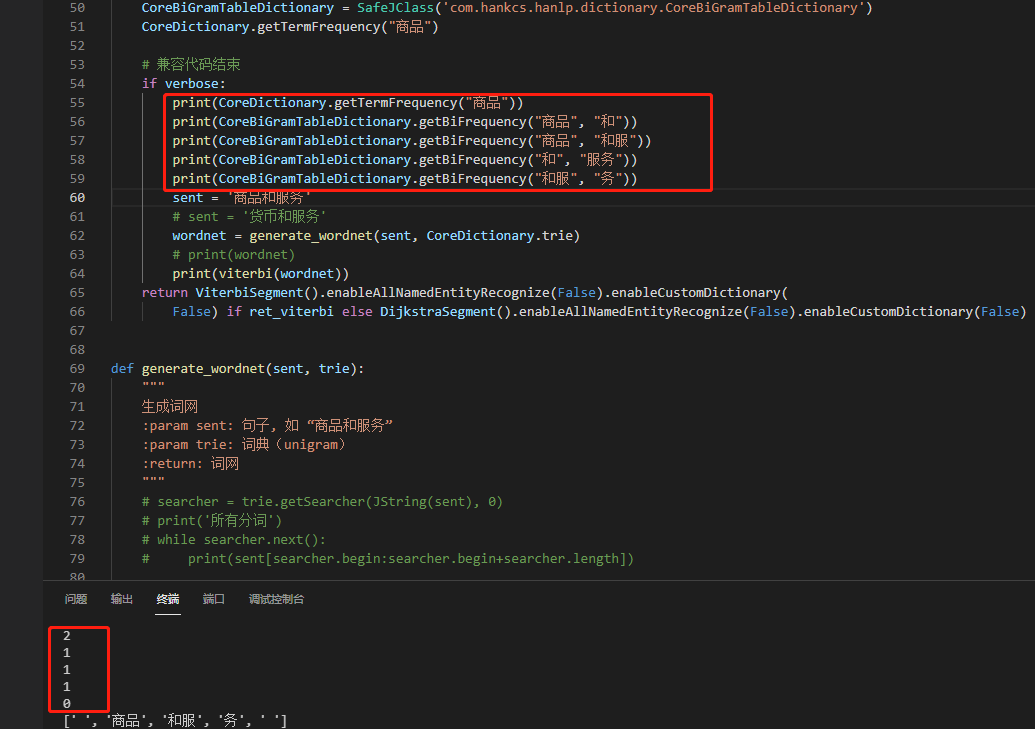
书中ch3的ngram_segment.py函数输出结果如下截图。但是分词结果跟书中不一样是为什么?
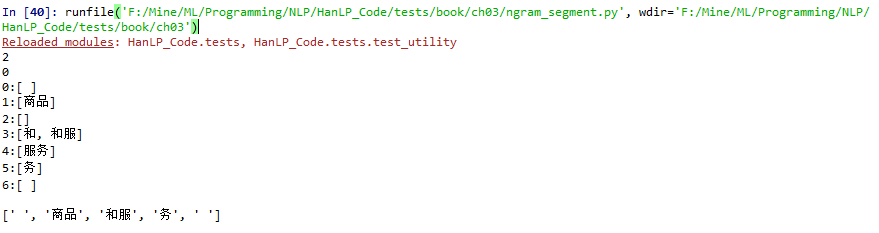
好像其他例程分词输出也全部有问题

检查文件编码,或者用Linux。
用的就是linux环境,语料上增加了很多商品和服务这种,为了增加2元语法的概率。但是出来的结果依旧是这样,请问是哪里出了问题??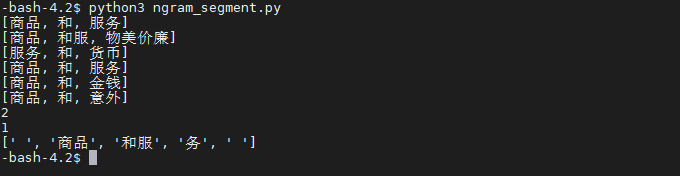
使用默认语料,查看如下bigram的频次:
print(CoreBiGramTableDictionary.getBiFrequency("商品", "和"))
print(CoreBiGramTableDictionary.getBiFrequency("商品", "和服"))
print(CoreBiGramTableDictionary.getBiFrequency("和", '服务'))
print(CoreBiGramTableDictionary.getBiFrequency("和服", '务'))
得到:
1
1
1
0
很明显 和服@务 这条边的概率接近为0。你们的语料库十有八九编码不是UTF8,导致上述ngram甚至unigram的频次都为0。书里原理都讲了,请自行排查。
您好,hancs, 那个帖子被您关闭了,我只好在这里提问了,抱歉。问题依旧存在。
您好,用的是github直接下载的源码, 环境是linux, 添加作者hankcs的实例 :
print(CoreBiGramTableDictionary.getBiFrequency(“商品”, “和”))
print(CoreBiGramTableDictionary.getBiFrequency(“商品”, “和服”))
print(CoreBiGramTableDictionary.getBiFrequency(“和”, ‘服务’))
print(CoreBiGramTableDictionary.getBiFrequency(“和服”, ‘务’))
将我之前跑过代码产生的static/data/test的my_cws*文件全部删除,直接运行文件 ngram_segment.py运行的结果如下:
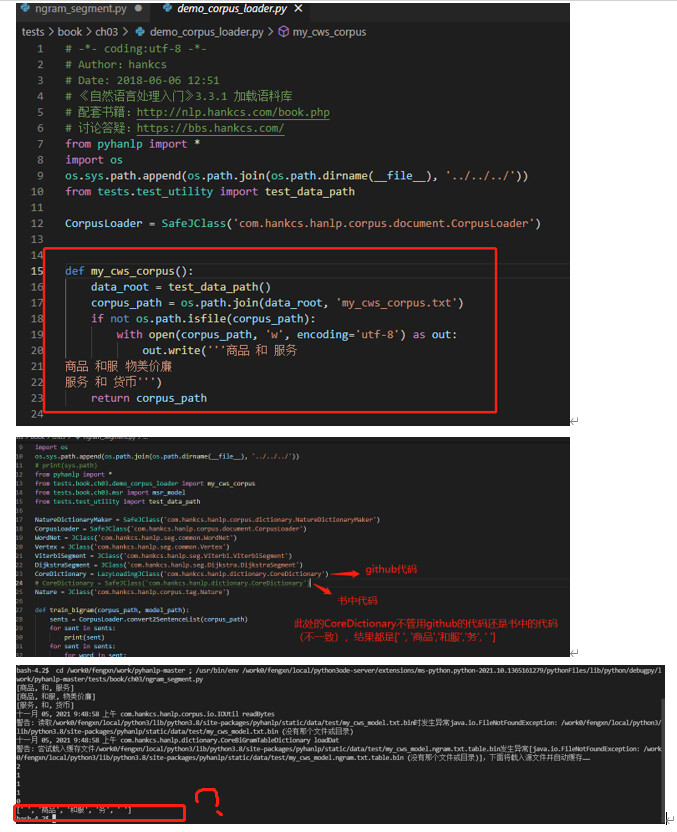
试了几种方法, 很明显和作者的结果一致, 和服@务 这条边的概率接近为0。但是结果和书本不一致,依旧不如人意,依旧是[’ ', ‘商品’, ‘和服’, ‘务’, ’ ']。
请问是哪里的问题呢?
@Wzf
将Wzf遇到的同样的问题,将运行ngram_segment.py产生的文件my_cws_model.txt.bin手动删除,再次运行ngram_segment.py,结果还是[’ ', ‘商品’, ‘和服’, ‘务’, ’ ']
感谢指出,问题的本质是新版本1.8.2改进了打分公式,将to节点词频纳入考虑。当to节点为未登录词“务”时,默认词频为1万,直接导致概率过大。HanLP的1.x分支已经修复了这个问题:
对于pyhanlp用户,请参考下列补丁:
不是同一个问题,1.8.2是最近才发布了,以前的都是编码非utf8的问题。