
何博士,你好:
- 请问设为词性标签这种方式有没有一个简单的格式例子,有点疑惑,范例中这种 {‘自定义’: ‘NZ’} 是不是也可以算作为 词性标签,模型中与自定义词典 中 相同的词语 有没有 匹配优先级 这样的说法呢 ?
- 另外我在使用中发现hanlp2.0中分词的时候,有一段代码中是去判断Char 是否属于 B or S 并截断词语,这里面出现一个问题:前置标注的Tags中,有时会把 如 H= 中 = 标识为 非B/S 的 E 情况,不知道这是不是一个Bug.
截图如下:
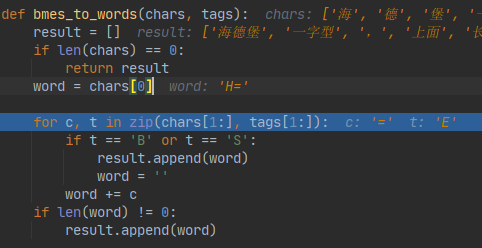
在该词前面5个数组下标中 = 属于正常的S tag,但在此处属于E tag,所以返回的word 有点不正确,请问这种情况应该怎么去修复
3.还想请问一下,hanlp2.0是否有出深度学习相关的书,想购买 您书写的 自然语言处理 那本书,又有些不明白里面是不是只有针对于1.0的版本的内容,2.0的内容是否会重新出一本书