
RTX3080对应的cuda版本为11.1
而hanlp依赖的tensorflow2.3只支持cuda10.1。
是否可以通过手动升级tensorflow 版本使程序运行?不知道兼容性怎么样。
你可以试试手动升级,但tf的Python端兼容性很差,不做保证。tf serving倒是兼容性不错。你都升到HanLP2.1了,为什么不试试新的MTL模型呢?准确率和速度都比tf模型要高,PyTorch不香吗?
是否可以出一个不需要tf的版本啊,每次制作docker镜像,带个tf让镜像很大啊 
2.1默认不依赖tf,只要不加载tf模型就不会import tf,pip install hanlp[full]才依赖。
重新优化了构建流程,把tf 去掉了,节省大约600M空间,运行 mtl模型无问题


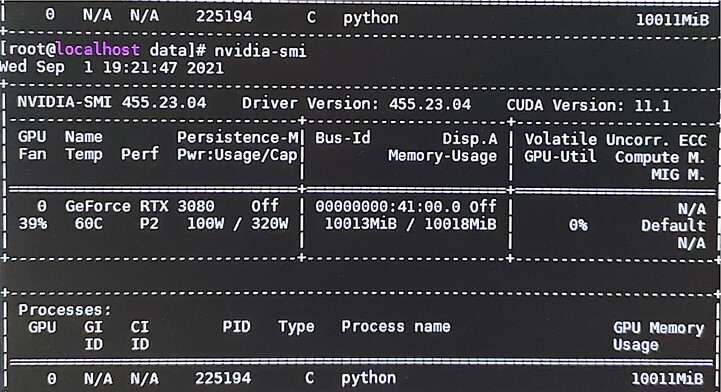
- 在
gradient_accumulation=1情况下,plugins/hanlp_demo/hanlp_demo/zh/train/open_small.py需要大约15G显存。 - 你可以根据自己的硬件条件增大
gradient_accumulation,可能4或者8适合你的情况。
非常感谢。将gradient_accumulation 设置成了4,一次epoch已完成,显存占用9265M。
还有关于模型评估这块,
以前用tf版本ner模型时,评估结果有具体的每一种实体类型的F值,
而mtl模型评估结果,只能看到综合指标了。
请问有什么方式可以快捷的得到每种实体类型的评估值吗
你得自行调用:
发现了一个小问题哈
执行到
hanlp.common.torch_component.TorchComponent.evaluate方法时,有一处evaluate_dataloader传参,save_dir 和 self.config中的save_dir有冲突,会报错:
TypeError: evaluate_dataloader() got multiple values for keyword argument ‘save_dir’
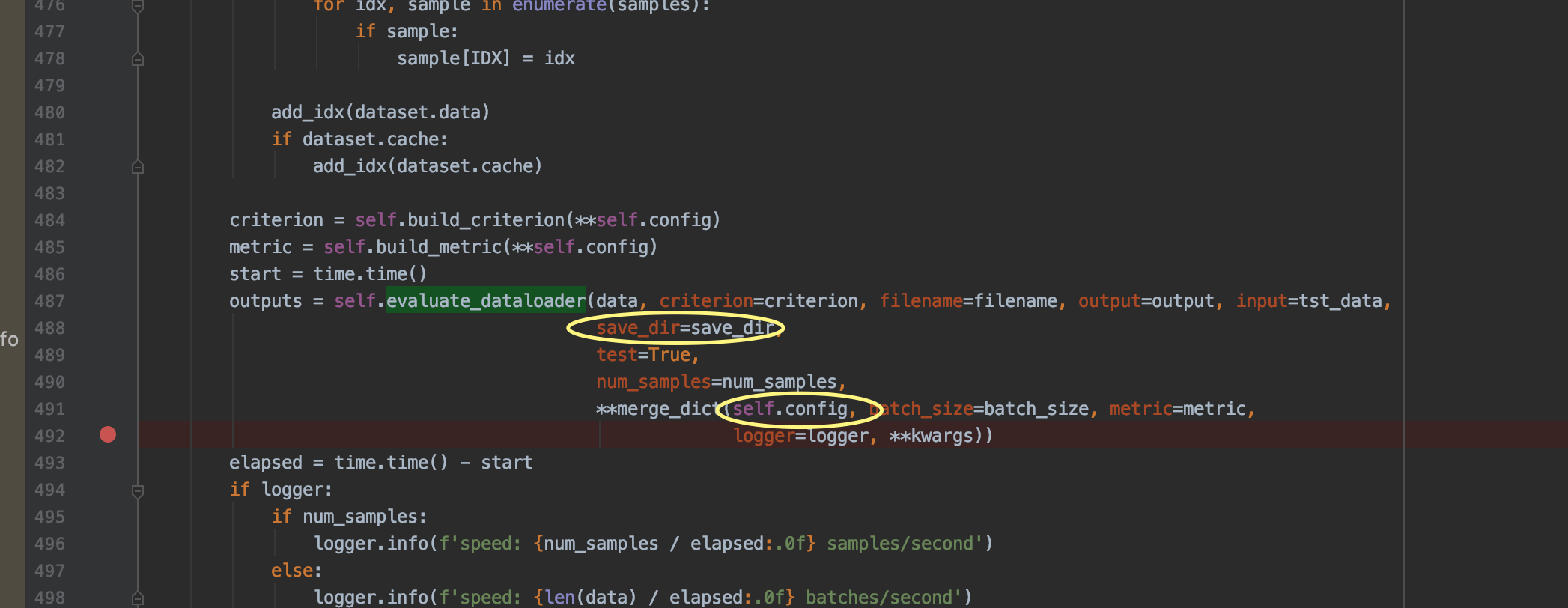
感谢指出,已经修复:
请升级 pip install hanlp -U