
不客气,CRF等模型都有词法分析接口,HanLP中的分词器都支持自定义词典。
1 Like
有自定义用户词典的提高分词效果的示例没有?用户自定义词典的词条是用于学习模型的特征使用,还是直接用于分词?
“HanLP中的分词器都支持自定义词典”, 请问,自定义词典在 2.0 版本是不是还在开发中?pynlp 中好像有。
1 Like
我跑这个例子,但得到的结果是 None:
In [37]: from hanlp.common.trie import Trie
…:
…: import hanlp
…:
…: tokenizer = hanlp.load(‘PKU_NAME_MERGED_SIX_MONTHS_CONVSEG’)
…: text = ‘NLP统计模型没有加规则,聪明人知道自己加。英文、数字、自定义词典统统都是规则。’
…: print(tokenizer(text))
…:
…: trie = Trie()
…: trie.update({‘自定义’: ‘custom’, ‘词典’: ‘dict’, ‘聪明人’: ‘smart’})
…:
…:
…: def split_sents(text: str, trie: Trie):
…: words = trie.parse_longest(text)
…: sents = []
…: pre_start = 0
…: offsets = []
…: for word, value, start, end in words:
…: if pre_start != start:
…: sents.append(text[pre_start: start])
…:
[‘NLP’, ‘统计’, ‘模型’, ‘没有’, ‘加’, ‘规则’, ‘,’, ‘聪明人’, ‘知道’, ‘自己’, ‘加’, ‘。’, ‘英文’, ‘、’, ‘数字’, ‘、’, ‘自定义’, ‘词典’,
‘统统’, ‘都’, ‘是’, ‘规则’, ‘。’]
**In [38]: print(split_sents(text, trie)) **
None
这个函数是展示用自定义词典来断句吗?这个词典怎么跟haNLP 自己的默认分词算法配合使用?

请问下命名实体识别能否采用挂载自定义词典的方式?我用现成的模型测试的时候有部分名字是无法识别的,如果可以采用挂载自定义词典的方式,那么也是用这个方法加自定义词典吗?我看你举的例子是采用键值对的方式挂载,那么命名实体的key应该是什么,value应该是什么?
同问,2.0版本可以增加自定义的NER吗?
您好,想问一下2.1版本的hanlp是否还支持以这样的形式加载自定义词典呢?我有试过这段代码,但是出现了问题,words = trie.parse_longest(text)返回的是a set of (begin, end, value),但是在for word, value, start, end in words:这句代码中就不适用了,我有将它改为for start,end ,value in words:,可是这样的话,就不能返回word了。
不知这段代码在2.1环境下要怎么修改呢?
我知道了,hancks老师对trie.py文件进行了修改,详见trie文件的修改,我的问题是在这个帖子里面看到的[https://bbs.hankcs.com/t/topic/2953/11](https://bbs.hankcs.com/t/topic/2953/11)
2.1新增了dict_whitelist,简化了这个流程:
1 Like
哇,这个设计太棒了,流程更加清晰了 
1 Like
小白拯救者,谢谢老师
想问一下老师,hanlp2.0的分词中是否可以以这种形式加载用户词典呢,我直接用HanLP[‘tok/fine’].dict_whitelist=self_dict 是没有效果的,不知道要怎么做呢?
有些词加了,是没有效果
类似于 一年内 两年内,三年内的 自定义 实体词 怎么加呢? 不支持正则表达式
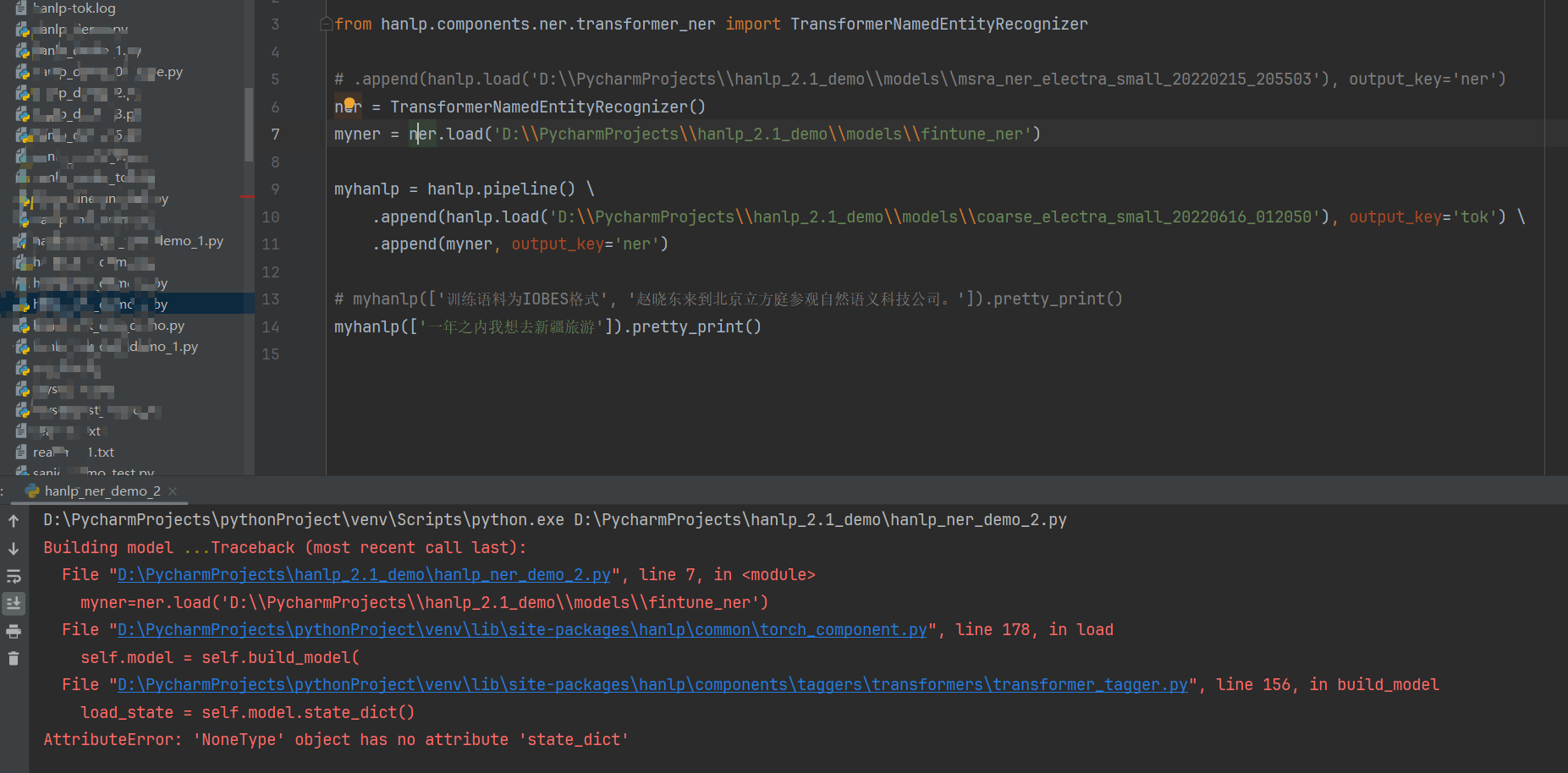
终于搞定成功了,ner.load()
请问是如何解决的啊?我也想加载finetune后的模型,但是不知道如何load