




以上1.x分词标注无问题。

以上1.x分词标注无问题。
有意思,看来lstm聪明过头了,字形的特征还有待加强。
@hankcs 大概2003年我搞了一版简单的分词,对分词一直比较感兴趣。去年我跟张华平聊过,我俩都觉得目前DL的方式,对分词没有太好的办法,除非加大训练素材,但是高质量的素材现在又找不到,这是个门槛
我赞同两位的观点,DL用来做分词是杀鸡用牛刀。目前HanLP2.0 alpha里的分词只是在一两个数据集上跑出了高分,离正式生产还有一段距离。
我认为DL做分词有前景:
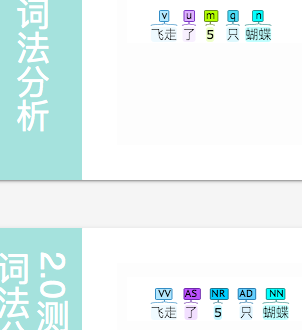
5只
测了一下,好像所有的 数词 + 只, “只”都被标成了 AD
建议在分词过程中加入量词数据集,并根据语义确定选定量词。