尊敬的何博士好:
我在nlp领域属于小白,因为工作的需要,恰巧需要这一块的知识。在一头雾水中发现了何博士的Hanlp源码以及相应的书籍这样的明珠,让我少走很多的弯路。也让我对nlp有了一些基础的认知。
通过阅读论坛的帖子,我了解到简单词用CWS+POS,复合词用NER,三者用LexicalAnalyzer组合起来。我的目标多为简单词,多以打算用CWS+POS。
我自定义建立了自己的分词库和标签库,以下为标签库部分数据,分词库与没有打标签的内容一致:
南京市/sj 建设委员会/jgdw 宣传处/cs 副主任科员/fk
南京市/sj 建设委员会/jgdw 宣传处/cs 主任科员/zk
南京市/sj 城乡建设委员会/jgdw 规划设计管理处/cs 主任科员/zk
南京市/sj 公安局/jgdw 政治部/cs 四级主任科员/fk
南京市/sj 发改委/jgdw 政治部/cs 四级主任科员/fk
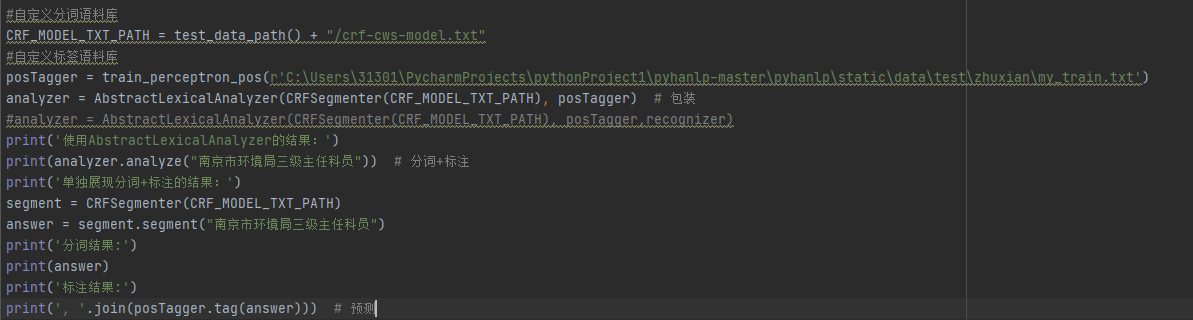
当我输入‘’南京市公安局三级主任科员’进行标注时,如果分步做segment与tag,我发现结果与我想要的一致。为南京市/sj 公安局/jgdw 三级主任科员/fk。
但当我使用AbstractLexicalAnalyzer时,结果为:南京市公安局/nto 三级主任科员/fk。无论是分词结果还是标签结果都错误了。甚至出现了nto这个可能来自pku库里的标签,这在我的自定义标签库里并未出现。
我又将输入换成“南京市环境局三级主任科员”,单独分别跑segment和tag,得到了我预料的结果。但是使用混种词法分析器后,结果为南京市/ns 环境局/jgdw 三级主任科员/fk。我不知道为何自己自定义打的标签被替换成了pku库中的ns。
我试图去阅读java源码,但是确实这一块的基础比较弱,没法看出什么端详。希望何博士百忙中能指点迷津,谢谢!以下为代码: