
何博士您好,本人参考了您的书籍,想做一个自定义领域的命名实体识别。之前使用感知机模型进行训练,可以得到输出结果。今天想尝试一下用CRF,采用Hanlp的java接口进行训练时,会报出语料错误,如下
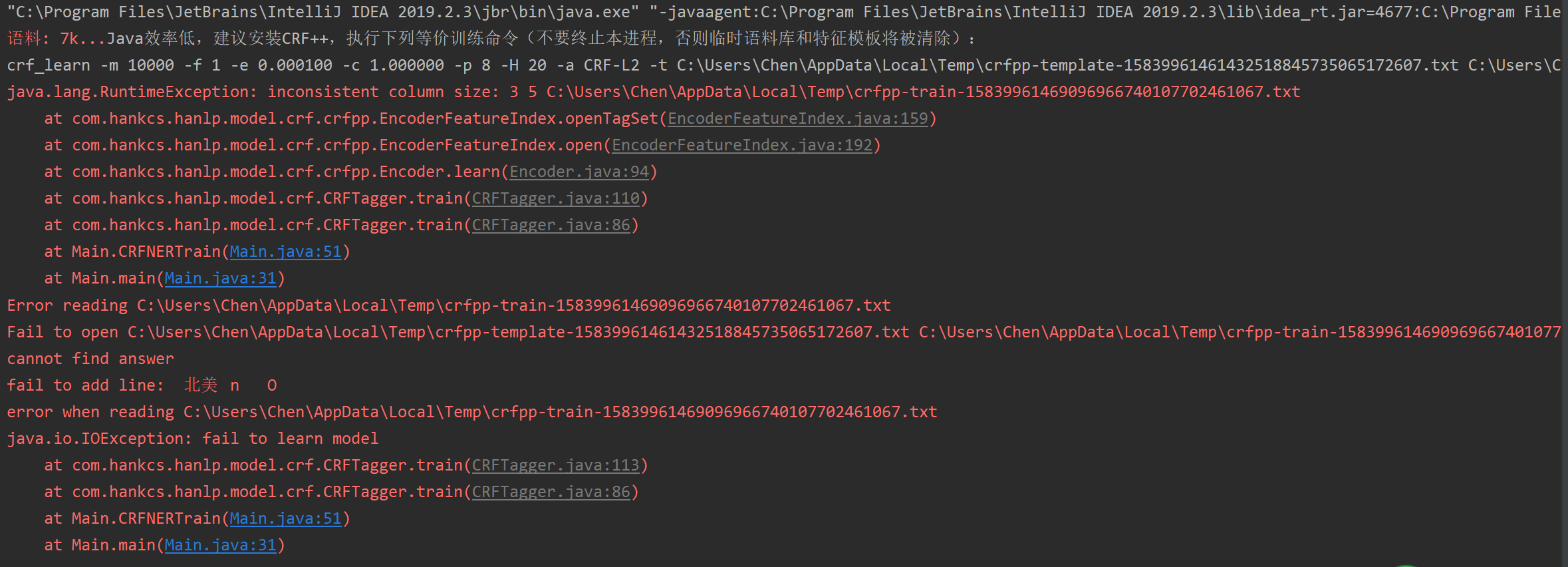
后来经检测 发现自动转换后的语料会在一些行的开头有空格,或者某些行只存在单个词而没有词性标记等问题。(这里有些疑问,就是为何转换后的语料会有此类问题)
在排查问题过后,采用了CRF++进行训练,命令按照您给出的参考
crf_learn cws-template.txt cws-corpus.tsv cws -t
特征模板为Hanlp导出的默认模板。但是命令运行之后,程序只显示读入文件而未进行迭代训练即退出,也未生成模型。显示如下:

经过网络查询,有人说是语料过大,确实经过语料删减只剩500000行时可以进行训练。不知道是不是语料过大这个问题,是否还有其他解决方案。还请指教。
另外训练平台是在自己的win10笔记本上