
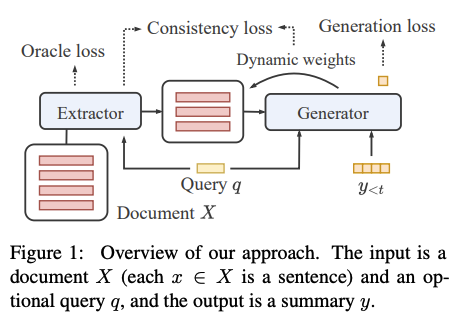
This paper proposes a clever method to jointly train an extractor and a generator to tackle long-input summarization. Their extractor assigns a score per each snippet, and their generator assigns both a generation probability and a dynamic weight to an extracted snippet. They force the averaged dynamic weight and the extractor distribution to be consistent such that there is no need to propagate gradient through top-k.
Comments
- Smart. Two components are trained end-to-end without resorting to RL.
- I feel this method is a little bit similar to the minimal risk training.
Rating
- 5: Transformative: This paper is likely to change our field. It should be considered for a best paper award.
- 4.5: Exciting: It changed my thinking on this topic. I would fight for it to be accepted.
- 4: Strong: I learned a lot from it. I would like to see it accepted.
- 3.5: Leaning positive: It can be accepted more or less in its current form. However, the work it describes is not particularly exciting and/or inspiring, so it will not be a big loss if people don’t see it in this conference.
- 3: Ambivalent: It has merits (e.g., it reports state-of-the-art results, the idea is nice), but there are key weaknesses (e.g., I didn’t learn much from it, evaluation is not convincing, it describes incremental work). I believe it can significantly benefit from another round of revision, but I won’t object to accepting it if my co-reviewers are willing to champion it.
- 2.5: Leaning negative: I am leaning towards rejection, but I can be persuaded if my co-reviewers think otherwise.
- 2: Mediocre: I would rather not see it in the conference.
- 1.5: Weak: I am pretty confident that it should be rejected.
- 1: Poor: I would fight to have it rejected.
0 voters