当我使用ner_tf 中的 TransformerNamedEntityRecognizerTF 微调MSRA_NER_BERT_BASE_ZH模型时,发现训练后的vocabs.json与微调之前不同。
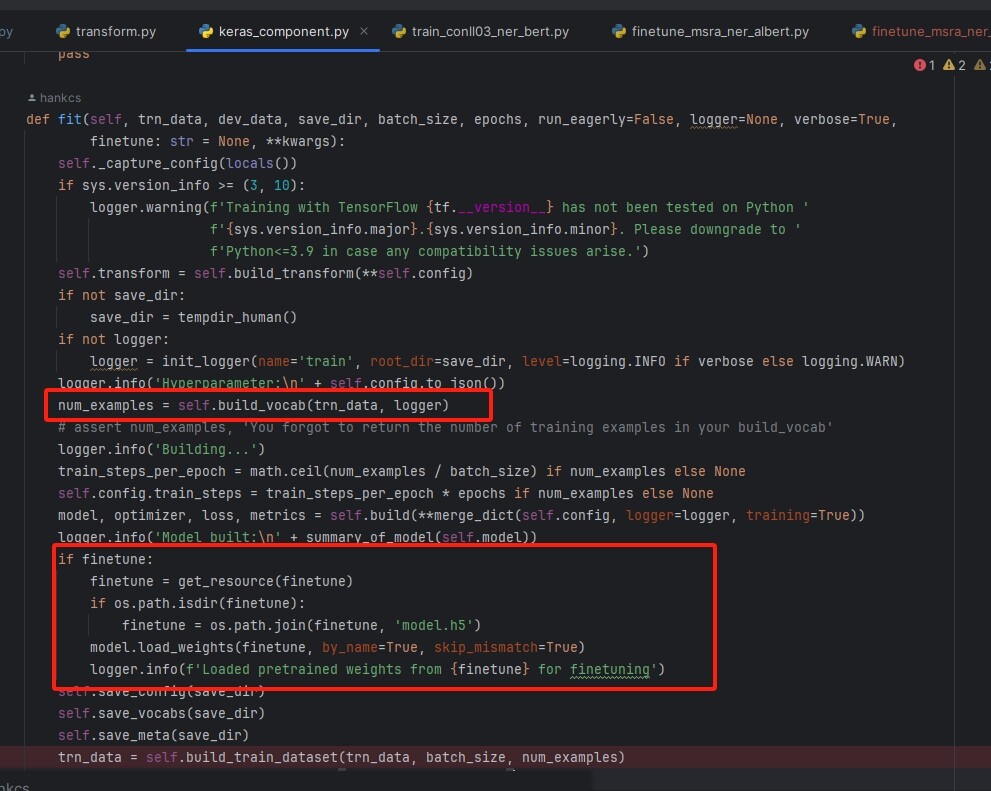
后面我查看源码,发现keras_component.py中if finetune:条件后面只有load_weights, 没有load_vocabs,而代码前面有num_examples = self.build_vocab()导致vocab新建立了。代码如下图
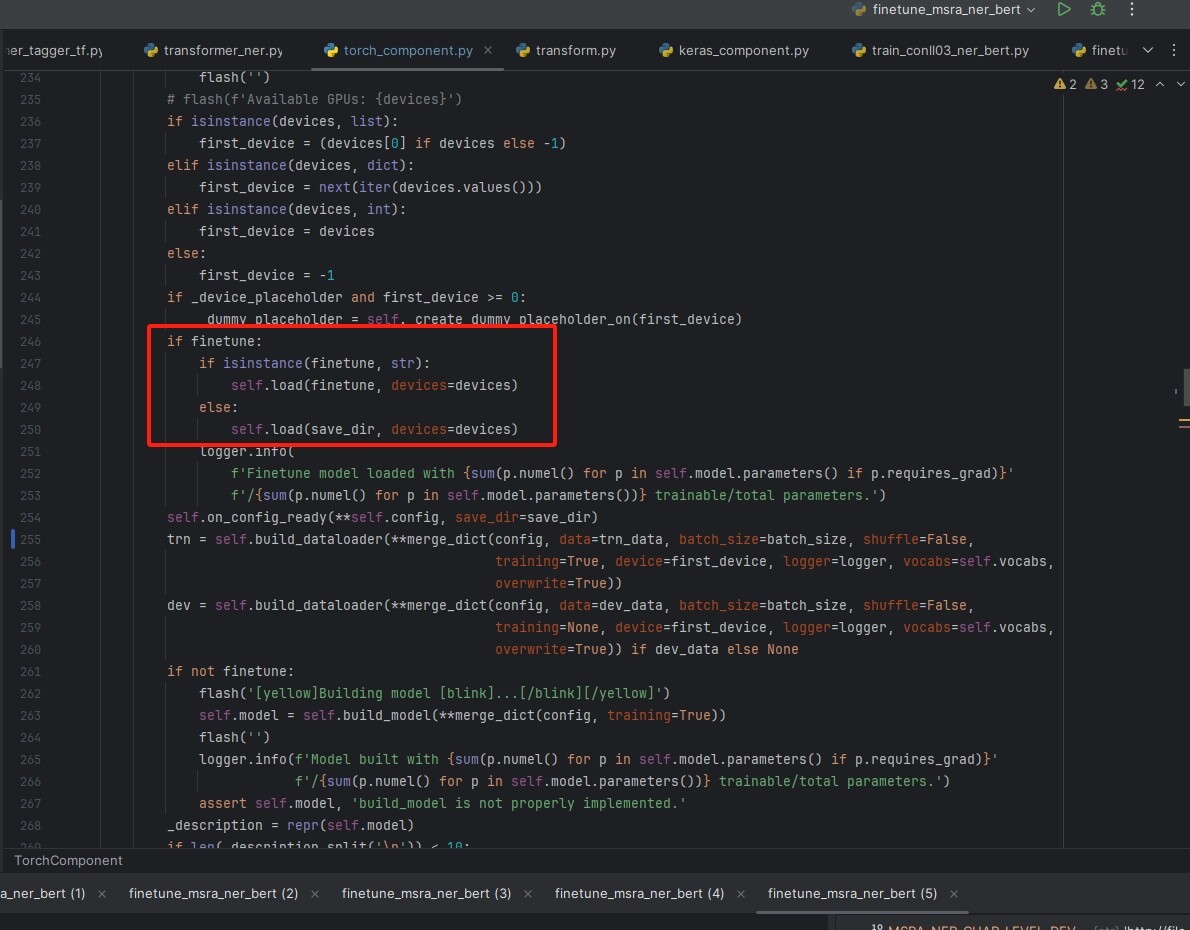
而我对比torch_component.py中的finetune条件,调用了load(), load()中调用了load_vocabs()所以正确的。
代码如下图