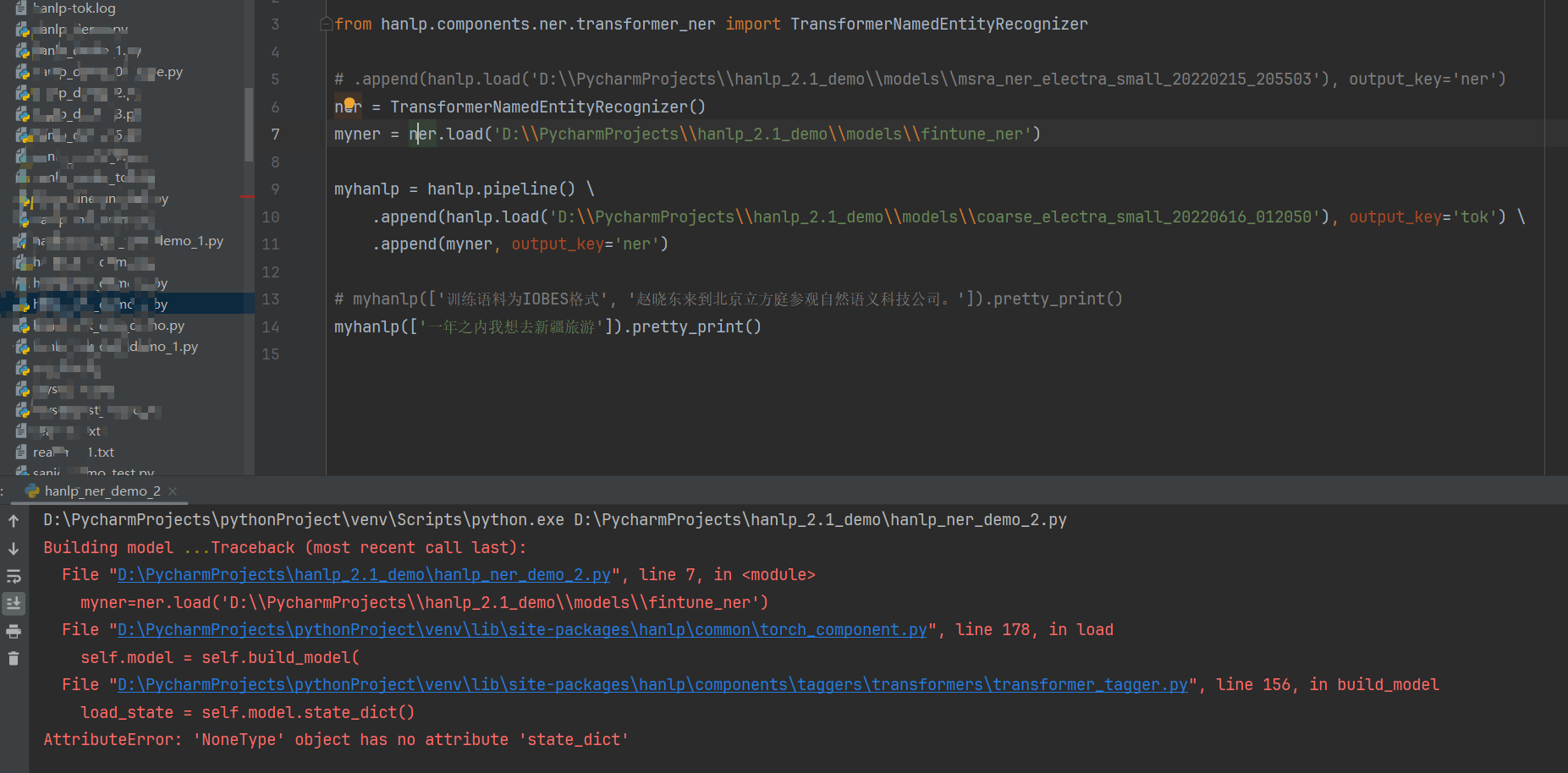
训练语料是自己准备的
在 O
格 B-HTL
瑞 I-HTL
斯 I-HTL
黄 I-HTL
金 I-HTL
海 I-HTL
岸 I-HTL
店 I-HTL
开 O
启 O
美 O
好 O
心 O
情 O
! O
发 O
现 O
一 O
个 O
海 B-LOC
南 I-LOC
海 I-LOC
口 I-LOC
一 O
个 O
必 O
打 O
卡 O
的 O
地 O
方 O
, O
美 O
哭 O
了 O
, O
热 O
带 O
雨 O
林 O
中 O
的 O
皇 O
家 O
庄 O
园 O
代码:
class Train(object):
def __init__(self, save_dir, epoch):
self.recognizer = TransformerNamedEntityRecognizer()
self.save_dir = save_dir
self.average_subwords = False
# self.trainset = trainset
# self.testset = testset
self.pretrained_model = hanlp.pretrained.ner.MSRA_NER_ALBERT_BASE_ZH
self.epoch = epoch
def fit(self, trainset, testset):
logging.info("Training...")
self.recognizer.fit(trn_data=trainset,
dev_data=testset,
save_dir=self.save_dir,
epochs=self.epoch,
max_seq_len=128,
average_subwords=self.average_subwords,
transformer='albert_base_zh',
finetune=self.pretrained_model
)
logging.info("Model saved in {}" % self.save_dir)
def predict(self, text):
rec_model = self.recognizer.load(self.save_dir)
ner_res = rec_model.predict(list(text))
return ner_res
报错:
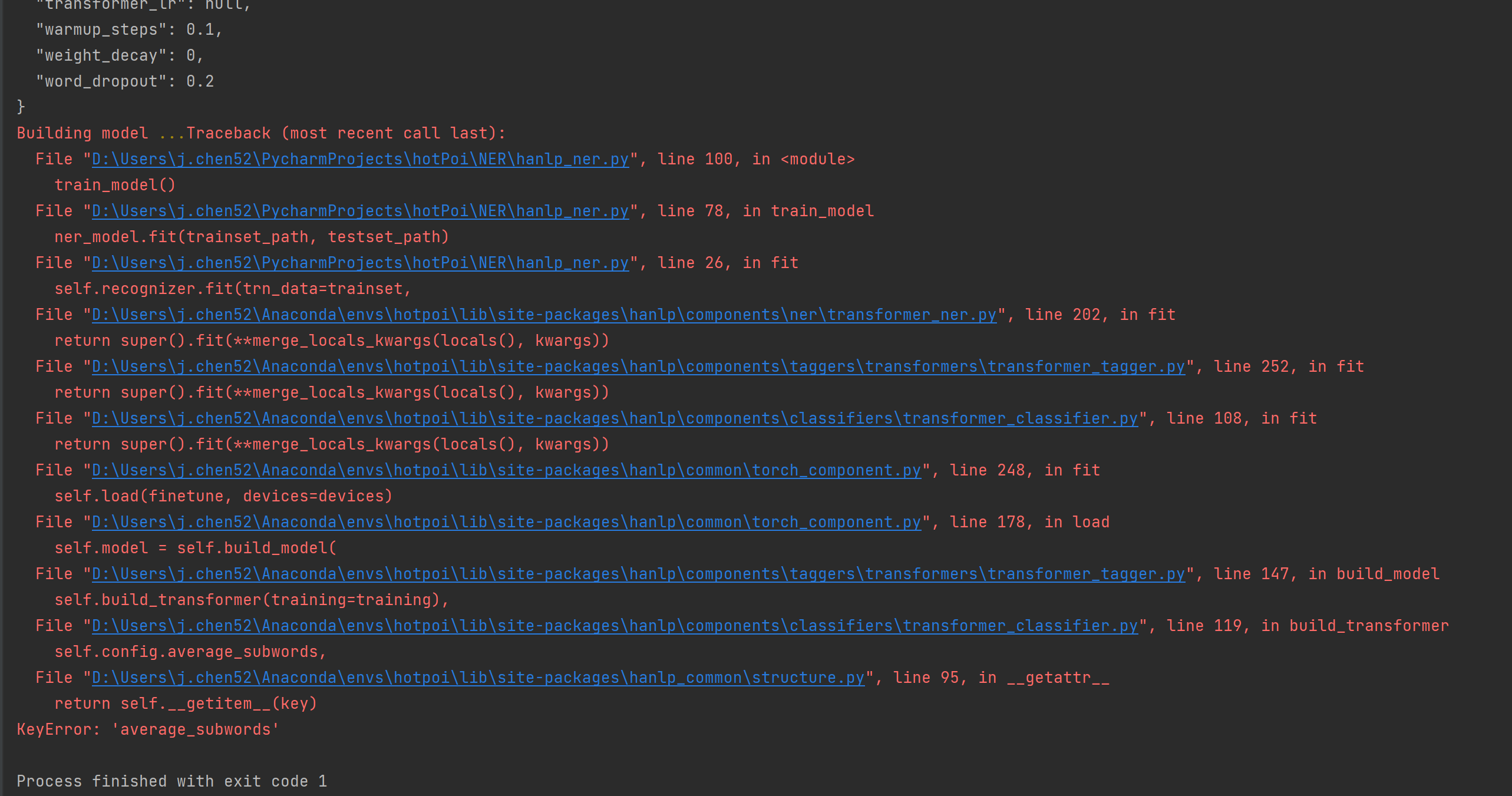
请问是什么原因呢?自己排查了好久都不知道。。。