
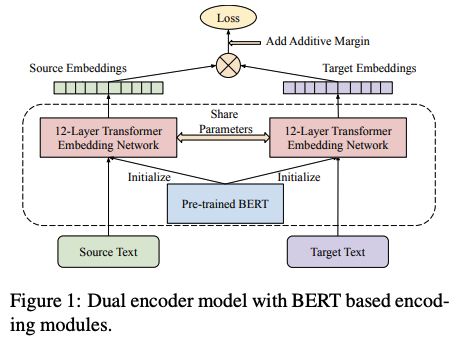
This paper investigates the effectiveness of pre-training for learning multilingual sentence embeddings by combining the best methods from MLM, TLM, dual encoder translation ranking and additive margin softmax. Their multilingual sentence embedding dramatically boosts the overall accuracy on 112 languages from 65% (prev SOTA) t0 83% on UN translation ranking task.
Comments
-
Yet another typical Google paper that scales several simple methods to beat SOTA.
- They didn’t really invent anything.
-
Using a customized and larger vocab seems to be the key for several low resource language.
-
LaBSE performs worse on pairwise English semantic similarity than other sentence embedding models, which is a little bit sad.
Rating
- 5: Transformative: This paper is likely to change our field. It should be considered for a best paper award.
- 4.5: Exciting: It changed my thinking on this topic. I would fight for it to be accepted.
- 4: Strong: I learned a lot from it. I would like to see it accepted.
- 3.5: Leaning positive: It can be accepted more or less in its current form. However, the work it describes is not particularly exciting and/or inspiring, so it will not be a big loss if people don’t see it in this conference.
- 3: Ambivalent: It has merits (e.g., it reports state-of-the-art results, the idea is nice), but there are key weaknesses (e.g., I didn’t learn much from it, evaluation is not convincing, it describes incremental work). I believe it can significantly benefit from another round of revision, but I won’t object to accepting it if my co-reviewers are willing to champion it.
- 2.5: Leaning negative: I am leaning towards rejection, but I can be persuaded if my co-reviewers think otherwise.
- 2: Mediocre: I would rather not see it in the conference.
- 1.5: Weak: I am pretty confident that it should be rejected.
- 1: Poor: I would fight to have it rejected.
0 voters