
A Permutation-invariant Semantic parser trained on MRP2020 English
and Chinese AMR corpus has been released. It was ranked the top in the MRP2020 competition.
This release made several enhancements on runtime speed and robustness. Please refer to the demo for furthur instructions: HanLP/amr_stl.ipynb at doc-zh · hankcs/HanLP · GitHub
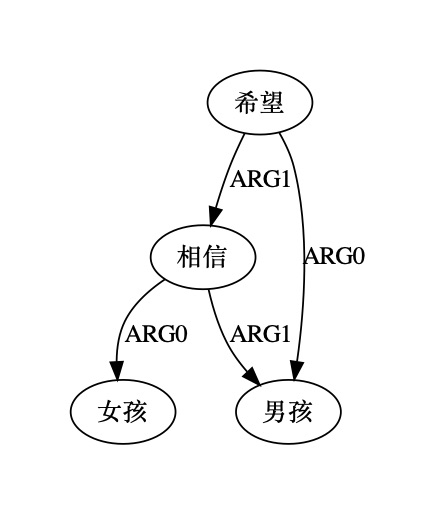
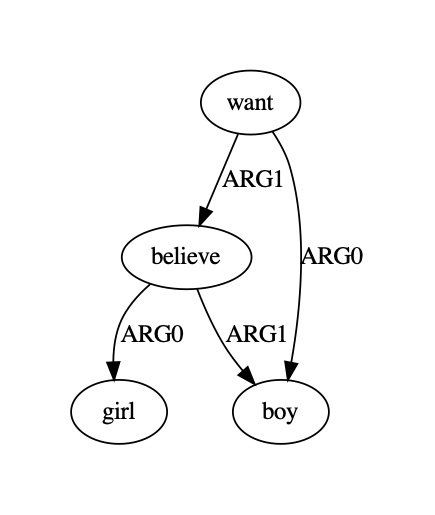
All the honors go to the paper authors:
 有段时间没来,发现更新了好多新模型啊!这几天测一下
有段时间没来,发现更新了好多新模型啊!这几天测一下