如何在sts模型的基础上提高某一领域内的短文本语义相似度
HanLP
Mr-IT007
July 25, 2022, 2:54am
#1
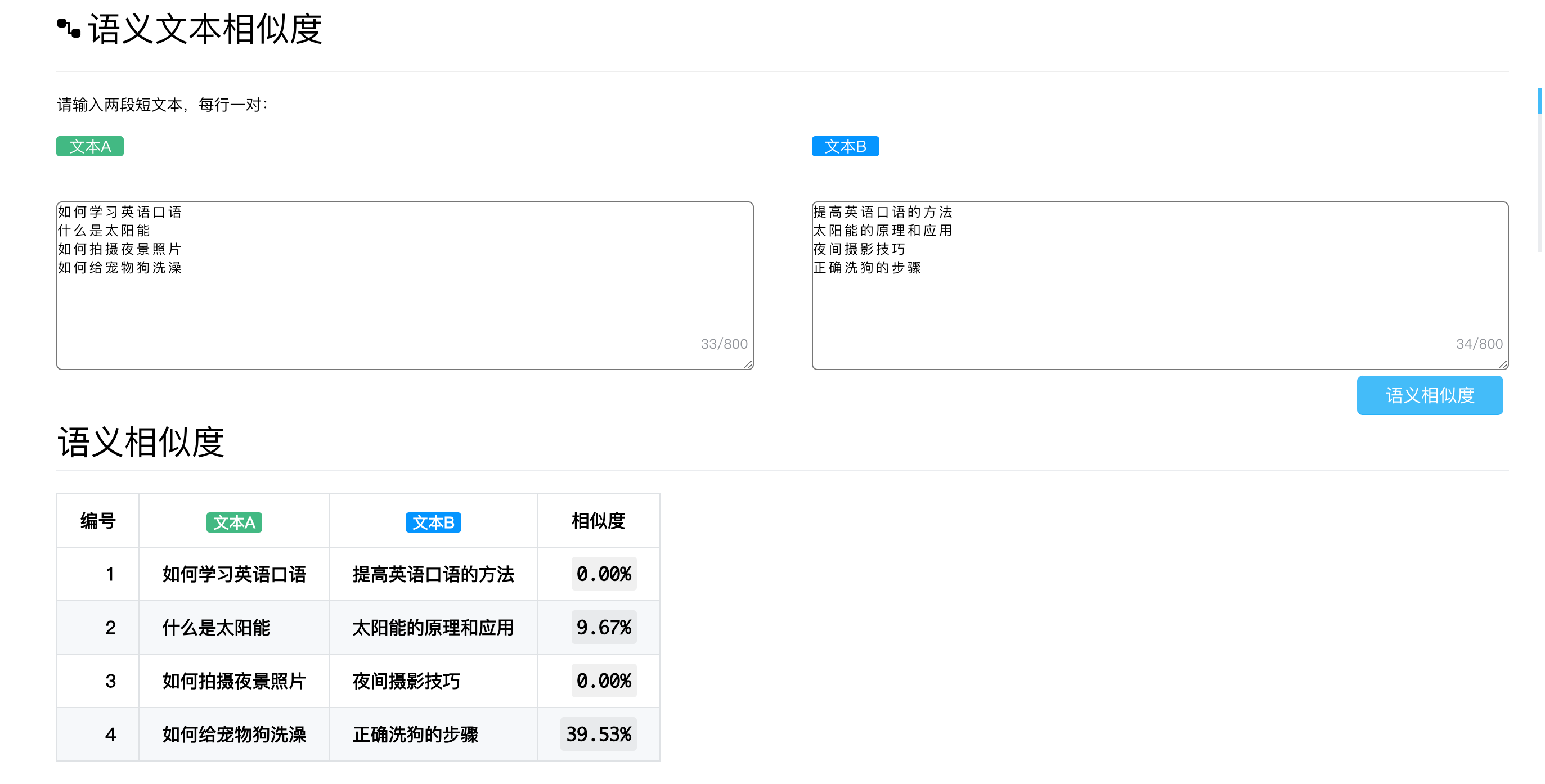
相似度
1022×342 30.8 KB
如上图,我想在sts的基础上提高上图短文本的语义相似度,我应该怎么做呢?
hankcs
July 30, 2022, 2:00am
#2
当前发布的模型还处于非常naive的阶段,训练数据仅有几个开源的数据集。我们正在研发一些无监督半监督的方法,敬请期待下次更新。
XingMingYue
July 24, 2024, 7:10am
#3
image
2746×1394 193 KB
现在有什么更好的方式吗,我试着线上的效果也不理想。
文档中的:HanLP的线上模型和语料库仍然在迭代发展中,当前版本存在打分两极分化的缺点。 我们将在下个版本修复这些问题,并且支持更多细分领域,敬请期待。
现在是否还在稳定推进?


 现在有什么更好的方式吗,我试着线上的效果也不理想。
现在有什么更好的方式吗,我试着线上的效果也不理想。