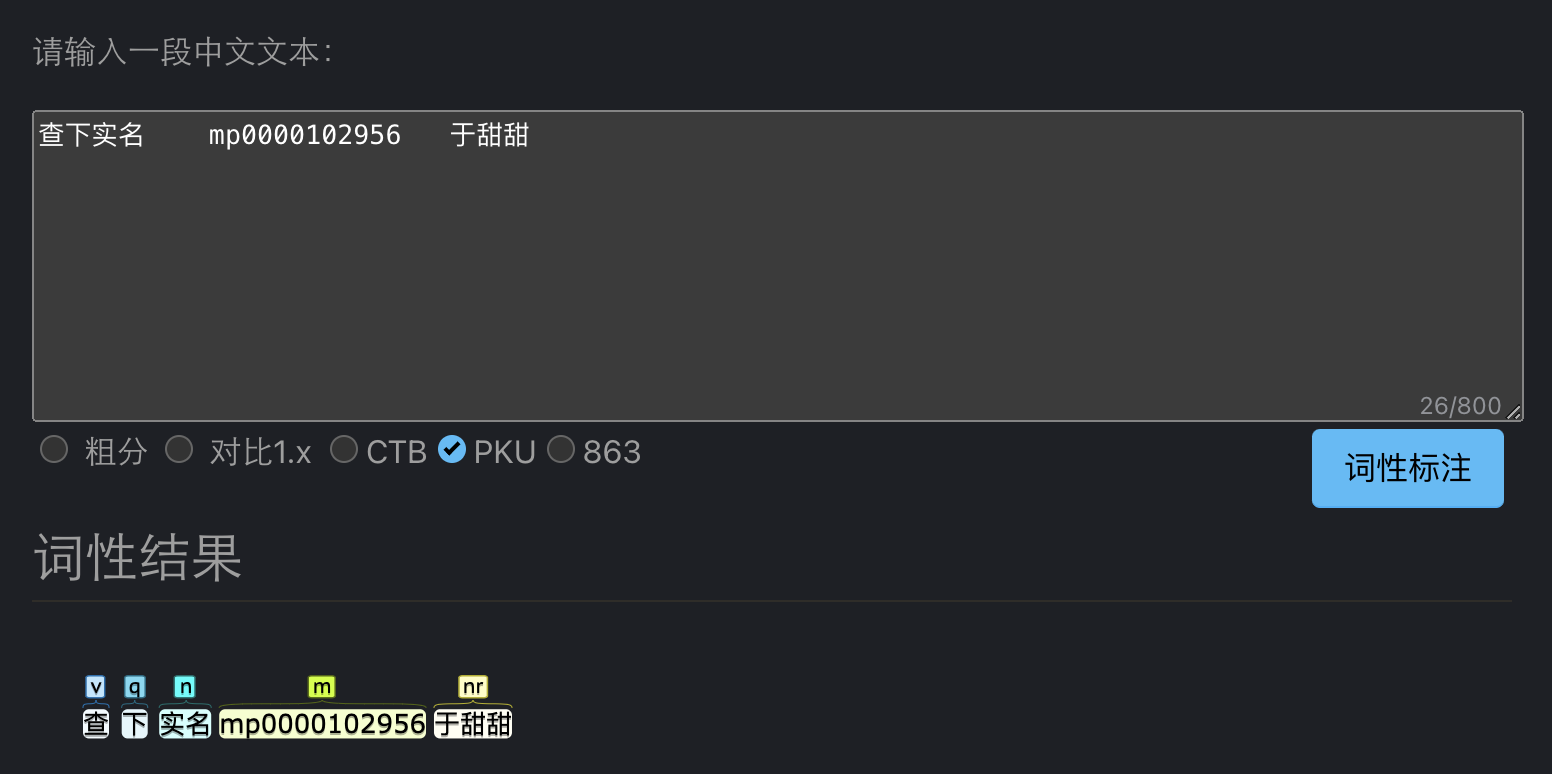
Hello here, I need some help. I used the part-of-speech tagging (PKU) but the result is not as accurate as on the demo page. What is model used in the demo page? How can I make it to achieve the same result?
Case: I have a text “查下实名 mp0000102956 于甜甜” and I want to extract a person name from it.
- On my code
hanlp.load(
hanlp.hanlp.pretrained.mtl.CLOSE_TOK_POS_NER_SRL_DEP_SDP_CON_ELECTRA_BASE_ZH
)
result = hanlp_mtl_base(text, tasks="pos/pku")
Result:
{
"tok/fine": [
"查",
"下",
"实名",
"mp0000102956",
"于",
"甜甜"
],
"pos/pku": [
"v",
"v",
"n",
"m",
"p",
"nr"
]
}
- On the demo page