
hankcs老师好,
还想请教一个关于自定义领域NER的问题。我有一些地名和街道名,默认的感知机模型没法识别出ns,不知道通过在线学习好,还是把标注好的新语料放入pku98后面重新训练好?
重新训练的话,是不是要在把新语料重复几次加到pku98再训练?有点怕语料较少还是无法正确识别。
如果在线学习,可以一直学习到模型能正确识别为止,但能否保存新模型呢?要不然每次运行脚本都要重新学习。
希望得到您的建议,谢谢!
建议放到pku里重新训练,因为在线学习不能创建新的特征。你可以随机将地名里的地名片段替换为同级的地名,比如“北京”替换为“上海”,来达到数据增广的效果。在线学习可以保存模型,模型有save接口,你去看看代码里的接口就知道。
好的,谢谢啦。我去看一下代码,这方面看得太少了。谢谢指点,我去重新训练模型
还有一个问题,感知机是随机算法,所以对有些词有时候能分对、有时候分不对?我发现有这种情况。那会不会对一些书上的示例,比如“温州黄鹤皮革制造有限公司是由黄先生创办的企业”也存在一定的概率分不对?尽管这种概率可能很小?如果这样的话,如果工程上要求稳定性,是不是就不推荐感知机的算法?而更好的是使用条件随机场?但其实我个人还是喜欢感知机的,因为准确率也不错,训练速度还快。不知道这种担心是否多余?谢谢
随机算法指的是训练产生的模型权值是随机的。一个例子不能反映模型的好坏。
嗯好的,谢谢,懂了
hankcs老师,
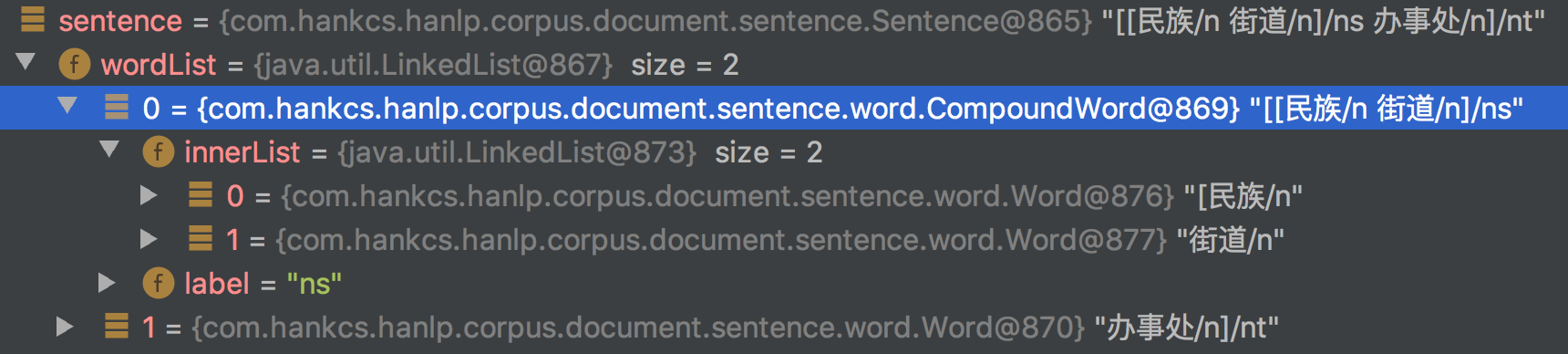
还想请问一个标注的基本问题。我自己的语料库里面想这样标注:[[民族/n 街道/n]/ns 办事处/n]/nt。我用感知机在线学习这句话,结果发现学习的结果一直是: 民族/n 街道办事处/nt。我注意到书中第7章中介绍pku标注集时,是有嵌套标注的现象,比如第36条,[[[欧盟/j 扩大/v]S 的/u [历史性/n 决定/n]NP]NP 和/c [北约/j 开放/v]S]NP-BL [为/p [创建/v [一/m 种/q 新/a 的/u 欧洲/ns 安全/a 格局/n]NP]VP-SBI]PP-MD [奠定/v 了/u 基础/n]V-SBI。但test目录下的pku语料库是没有这种嵌套标注的。
我的问题是:
(1)不知道这种嵌套标注的语料是否支持?
(2)我想让 韩家墩、韩家墩街道、韩家墩街道办事处 都能作为ns的命名实体被识别出来,如果嵌套标注不行的话,还有什么办法呢?
谢谢~
好的,太感谢了!我先自己再试试看~
定义一个自定义词典:
韩家墩 gov_part 1
韩家墩街道 gov_part 1
韩家墩街道办事处 gov_part 1
inputLine=‘韩家墩、韩家墩街道、韩家墩街道办事处’
print(HanLP.segment(inputLine))
分词结果:
[韩家墩/gov_part, 、/w, 韩家墩街道/gov_part, 、/w, 韩家墩街道办事处/gov_part]
哈哈,多谢多谢,我也试试自定义词典
hello,想请问一下,自定义词典分词,把一些关注的地名打上自定义的词性标签,是不是从效率上几乎等价于手写的规则系统?如果用字符串匹配的算法来做,和打词性标签后,再基于分词器来做,从效率上有何差别呢?谢谢~