
Page 331页,12.2.3 依存句法树的可视化:
基于 Dependency Viewer 最新Update版本 Update date:June 6, 2012
打开Dependency Viewer之后,点击相应ICON可发现:
原文:利用菜单"File -> Read CoNLL File"即可加载一个.conll扩展名的树库文件;
建议更正:利用菜单"File -> Read Conll File"即可加载一个.conll扩展名的树库文件;
感谢指正。虽然书里的是CoNLL的正确拼写,但软件里面的确是小写的。
你好,对于256页的内容我有一点疑问,既然已经标注出了BCD,而标注规则里C代表双名首字,D代表双名末字,那按照这个规则,不是肯定出现了BCD作为人名吗?为何还会有BC、BCD两种可能呢?
你的疑问是合理的,前提是HMM的预测是100%准确的。然而在实践中,HMM很难区分D与L,导致有些BCL被标记为BCD。这时候将结果输入到第二级HMM中进一步修正,可以部分解决这个问题。
认真负责,点赞 
1 Like
是62页,勘误表中误作41页了。
感谢指正 
P295。……遍历剩下的所有数据点,若该点到最近质心的距离的平方小于 \Delta ,则选择该点添加到质心列表……
此处似应为“若该点到最近质心的距离的平方大于 \Delta ” ?查看源代码也是:
double randval = random.nextDouble() * potential;
for (index = 0; index < documents_.size(); index++)
{
double dist = closest[index];
if (randval <= dist)///这是距离大于Delta吧?
break;
randval -= dist;
}
感谢指出错误,这里的确误写为小于。选取初始质心时,应当尽量分散,质心之间的距离应该尽量大。那些偏离质心太远的点应当作为新的质心。
我刚买的书,2019年10月第1版,2021年5月天津第10次印刷。
我看了一下,至少前三个勘误(41页、62页、86页)在书中已经修改过了。

的确如此,感谢指正。
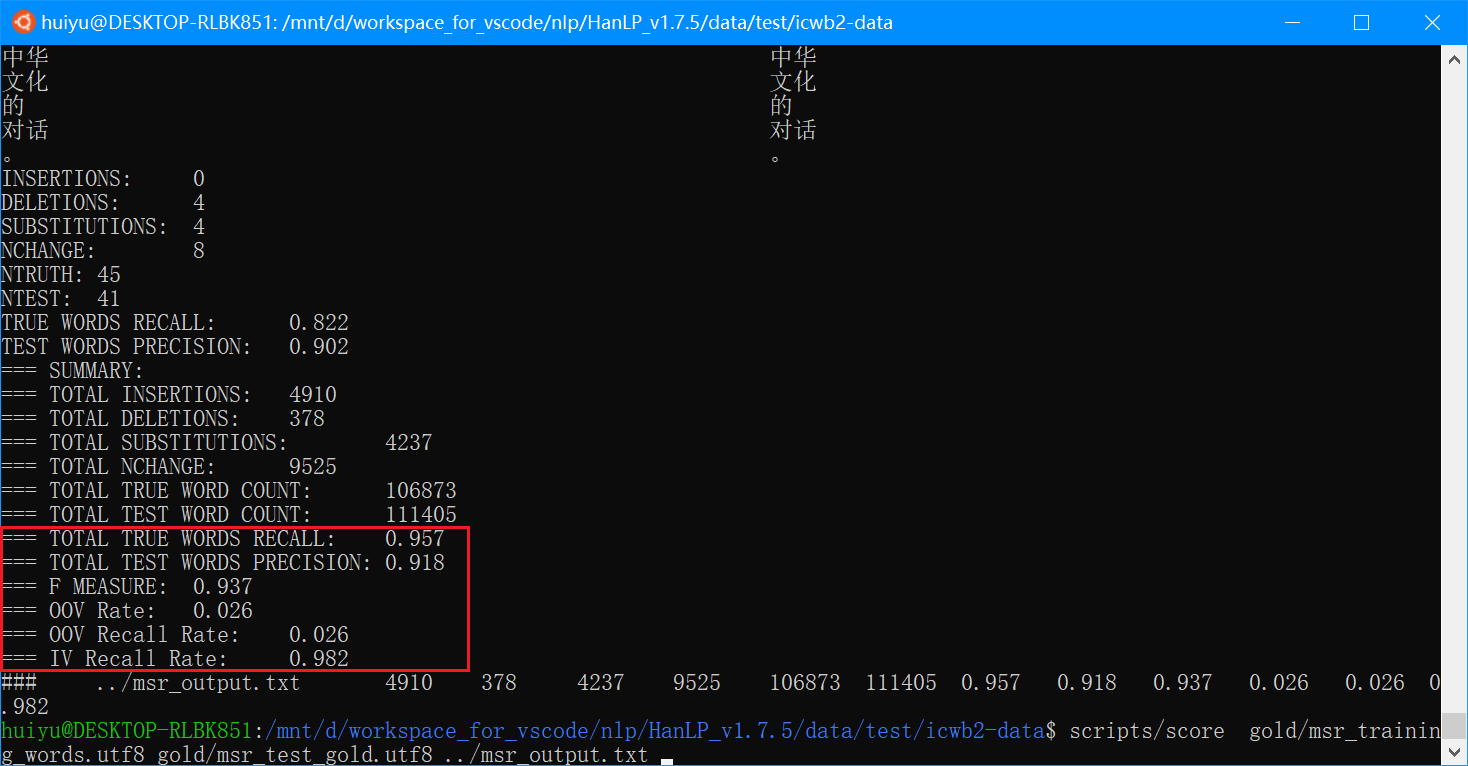
我运行evaluate_cws.py和官方评分脚本icwb2-data/scripts/score得到的结果比书中的值要高一些。
官方评分脚本的结果:
evaluate_cws.py的结果:
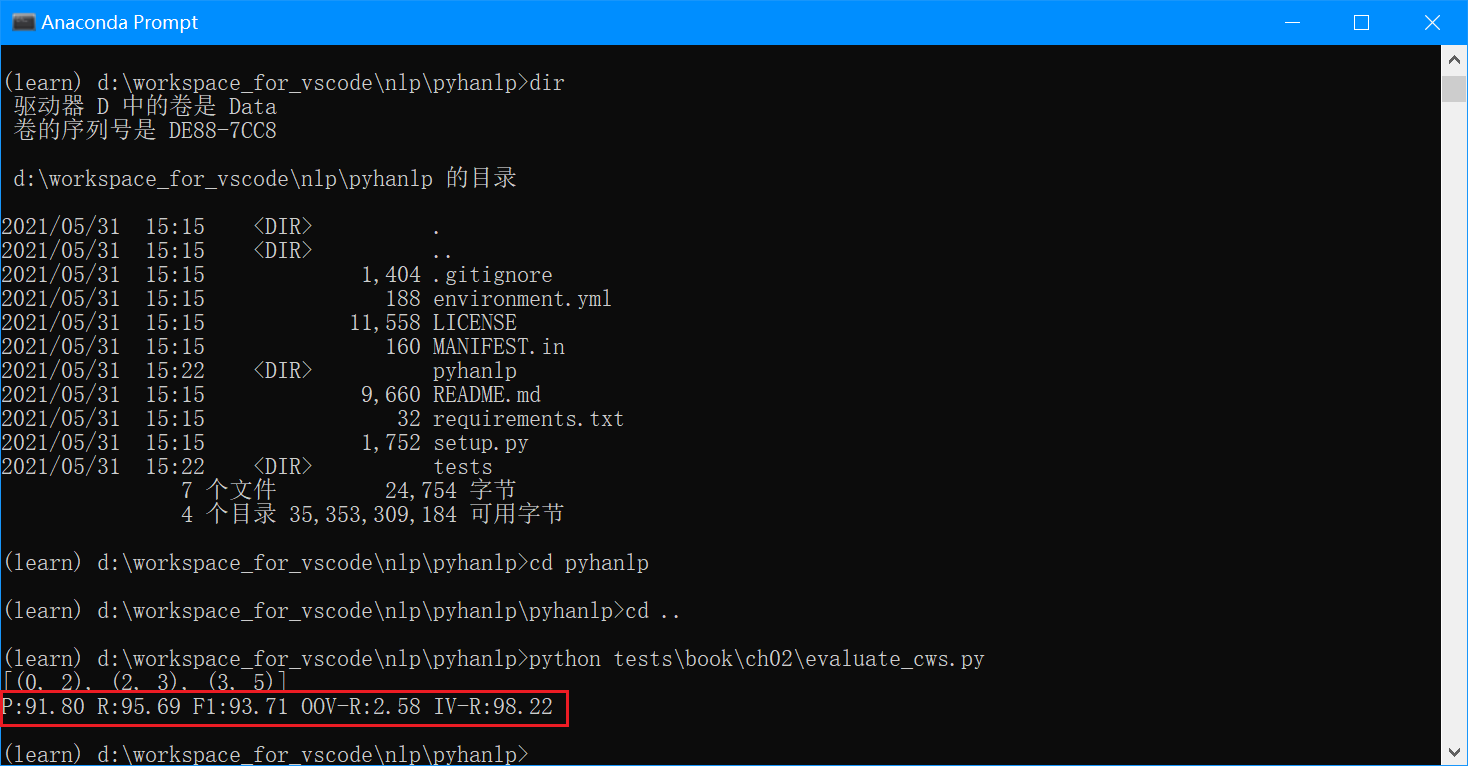
两者结果一致(P:91.80 R:95.69 F1:93.71),但是比书中的值(P:89.41 R:94.64 F1:91.95)要高。
我用的是data-for-1.7.5.zip。书中用的不是这个数据集吗?
参考页码:80至83
感谢细心地指出,写作前前后后花了一年多,开发版本迭代了好几版。有可能是因为写第二章的时候使用了低版本的HanLP,后来在1.7.5中改进了一些细节,提高了分数却没有更新第二章的表格。请以当前的分数P:91.80 R:95.69 F1:93.71 OOV-R:2.58 IV-R:98.22为准,我会更新书中的相应数据。

感谢质疑,
问题1
这个经验公式是根据张华平教授的开源代码总结出来的,根据该代码,分母的确是 c(w_t) ,即当前单词的词频。参考几年前的讨论:
这个经验公式的设计的确与拉普拉斯平滑重复了。从数学自治的角度来讲,高阶用低阶插值平滑。应该bigram概率用unigram平滑,unigram概率用一个常数比如 \mu = \frac{1}{N} 平滑。这里的bigram概率已经用unigram平滑了一次,的确不需要再用 \mu 去平滑。
问题2和3
这同样是个历史遗留问题,请参考:
后来没有修复的原因是做过试验,使用现在较大的常数 MAX_FREQUENCY 在MSR上的结果是:
P:92.38 R:96.70 F1:94.49 OOV-R:2.58 IV-R:99.26
而使用正确的总词频+词语种数(2542227 + 88121)的结果是:
P:92.32 R:96.68 F1:94.45 OOV-R:2.58 IV-R:99.23
当使用标准的拉普拉斯平滑并且去掉 \mu 平滑时:
int frequency = from.getAttribute().totalFrequency;
int nTwoWordsFreq = CoreBiGramTableDictionary.getBiFrequency(from.wordID, to.wordID);
double value = -Math.log(dSmoothingPara * (frequency + 1) / (2542227 + 88121) + (1 - dSmoothingPara) * ((float) nTwoWordsFreq / frequency));
得到的结果是
P:91.26 R:96.20 F1:93.66 OOV-R:2.58 IV-R:98.75
除了OOV-R是规则产生之外,其他的统计指标都越变越差。可见实际项目dirty的一面,按照教科书规规矩矩走反而得不到最好的效果,经验公式还是有存在的价值。
关于newB和newE的频次问题,对分词结果几乎没有影响,使用常数可以减少查询,加快运行速度。
PS:论坛支持 \LaTeX ,你可以直接打公式。
感谢解答。
关于公式3.2,calculateWeight中分母上的frequency是from.getAttribute().totalFrequency,对应的是 C(w_{t-1}) ,与公式3.2不符。
Latex不太会用 
的确,感谢指出错误!
关于第111页的公式3.2,我还是觉得分母上应该使用 c(w_{t-1}) 。前半部分是MLE的 p(w_t|w_{t-1}) ,后半部分平滑 c(w_t) 为零时的概率。如果将前半部分的分母改为 c(w_{t}) ,怎么解释?
而且我试了一下,分母使用 c(w_{t-1}) 之后,结果更好。
原版在MSR的评测结果是
P:92.38 R:96.70 F1:94.49 OOV-R:2.58 IV-R:99.26
仅修改calculateWeight,分母使用 c(w_t) ,N为固定值25146057,结果是
P:92.28 R:96.64 F1:94.41 OOV-R:2.58 IV-R:99.20,不如原版。
仅修改calculateWeight,分母使用 c(w_{t-1}) ,N为固定值25146057,结果是
P:92.52 R:96.79 F1:94.61 OOV-R:2.58 IV-R:99.36,比原版有所提高
仅修改calculateWeight时,代码如下:
public static double calculateWeight(Vertex from, Vertex to)
{
int cFrom = from.getAttribute().totalFrequency; // C(Wt-1)
int cTo = to.getAttribute().totalFrequency; // C(Wt)
int cFromTo = CoreBiGramTableDictionary.getBiFrequency(from.wordID, to.wordID); // C(Wt-1Wt)
double lambda = 1 - dSmoothingPara;
double miu = 1 - dTemp;
int N = MAX_FREQUENCY;
double value;
// 分母为C(Wt-1)
if (cFrom == 0) {
value = lambda * (1 - miu) + (1 - lambda) * (cTo + 1) / N;
} else {
value = lambda * (miu * cFromTo / cFrom + 1 - miu) + (1 - lambda) * (cTo + 1) / N;
}
// // 分母为C(Wt)
// if (cTo == 0) {
// value = lambda * (1 - miu) + (1 - lambda) * (cTo + 1) / N;
// } else {
// value = lambda * (miu * cFromTo / cTo + 1 - miu) + (1 - lambda) * (cTo + 1) / N;
// }
value = -Math.log(value);
if (value < 0) {
// 理论上来说此处不会出现value小于零的情况,除非C(Wt-1Wt)、C(Wt)、C(Wt-1)或N的值有误。
// 只要满足C(Wt-1Wt)不超过C(Wt)或C(Wt-1),C(Wt)小于N,那么value就不会小于零。
// 如果是统计得到的数值,那么一定满足上述条件。
System.err.println(value);
value = -value;
}
return value;
}
修改其他代码后,结果还能进一步提高。
P:92.62 R:96.85 F1:94.69 OOV-R:2.58 IV-R:99.41
改动点为:
- 加载字典时更新MAX_FREQUENCY,重新计算dTemp,并记录词语种数(Predefine.WORD_COUNT)
- 新建开始节点和结束节点时,频率设为字典中对应的频率。
- 原子分词结果的频率设为零,这些都是OOV的。
上述修改之后可以保证calculateWeight中value在取对数前肯定大于0,小于1。
具体改动如下:
calculateWeight中
N = MAX_FREQUENCY + Predefine.WORD_COUNT
分母使用 c(w_{t-1})
com.hankcs.hanlp.seg.common.Vertex
方法public static Vertex newB()
Predefine.MAX_FREQUENCY / 10改为CoreDictionary.getTermFrequency(Predefine.TAG_BIGIN)
方法public static Vertex newE()
Predefine.MAX_FREQUENCY / 10改为CoreDictionary.getTermFrequency(Predefine.TAG_END)
com.hankcs.hanlp.seg.common.WordNet
方法public void add(int line, List<AtomNode> atomSegment)
第286行,new CoreDictionary.Attribute(nature, 10000)改为new CoreDictionary.Attribute(nature, 0),因为进入原子分词都是字典中没有的词,所以其频率为零。
com.hankcs.hanlp.utility.Predefine
public static final int MAX_FREQUENCY = 25146057; // 现在总词频25146057
/**
* Smoothing 平滑因子
*/
public static final double dTemp = (double) 1 / MAX_FREQUENCY + 0.00001;
改为
// 词语种数
public static int WORD_COUNT = 0;
public static void setParams(int max, int count) {
WORD_COUNT = count;
MAX_FREQUENCY = max;
dTemp = (double) 1 / max + 0.00001;
}
// 词频总数
public static int MAX_FREQUENCY = 25146057; // 现在总词频25146057
/**
* Smoothing 平滑因子
*/
public static double dTemp = (double) 1 / MAX_FREQUENCY + 0.00001;
com.hankcs.hanlp.dictionary.CoreDictionary
方法private static boolean load(String path)中添加添加
trie.build(map);
// 记录词频总数和词条数量
Predefine.setParams(MAX_FREQUENCY, map.size());
logger.info("核心词典加载成功:" + trie.size() + "个词条,下面将写入缓存……");
方法static boolean loadDat(String path)中计算词频总数
static boolean loadDat(String path)
{
try
{
ByteArray byteArray = ByteArray.createByteArray(path + Predefine.BIN_EXT);
if (byteArray == null) return false;
int maxFreq = 0; // 词频总数
int size = byteArray.nextInt();
CoreDictionary.Attribute[] attributes = new CoreDictionary.Attribute[size];
final Nature[] natureIndexArray = Nature.values();
for (int i = 0; i < size; ++i)
{
// 第一个是全部频次,第二个是词性个数
int currentTotalFrequency = byteArray.nextInt();
int length = byteArray.nextInt();
attributes[i] = new CoreDictionary.Attribute(length);
attributes[i].totalFrequency = currentTotalFrequency;
maxFreq += currentTotalFrequency; // 累加词频
for (int j = 0; j < length; ++j)
{
attributes[i].nature[j] = natureIndexArray[byteArray.nextInt()];
attributes[i].frequency[j] = byteArray.nextInt();
}
}
// 设置词频总数和词语种数
Predefine.setParams(maxFreq, size);
if (!trie.load(byteArray, attributes) || byteArray.hasMore()) return false;
}
catch (Exception e)
{
logger.warning("读取失败,问题发生在" + e);
return false;
}
return true;
}
1 Like