
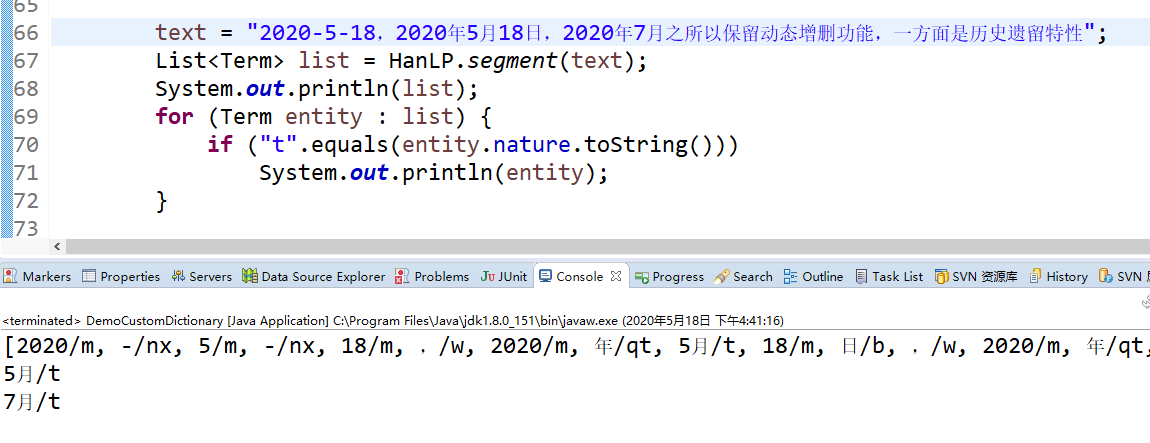
这两天开始学习hanlp,分词这块其他部分我没什么问题,包括自定义分词和排除的分词方法都使用成功。就是这个关于时间的处理有问题,我输入的是完整的时间,为什么提取出来的只有月份,其他的都是不一样的标签,想输出 “2020年5月18日”这样的结果,该如何处理?
我的理解是日期分词其实应该是属于命名实体识别的范畴, 而不是分词的范畴。 既然你已经尝试过自定义分词, 我觉得可以再分词器啊前wrap一层正则表达式, 将日期先提取出来并给予postag。具体可以参照hanlp 给出的url_tokenizer的例子https://github.com/hankcs/HanLP/blob/1.x/src/main/java/com/hankcs/hanlp/tokenizer/URLTokenizer.java
同时, 网上应该可以找到很多关于日期的正则。
1 Like
感谢,有办法做了
有帮助的话请给个赞~
怎么做的呢?
楼上例子是把文本拆成几段来分词了,被拆的句子不完整了吧!不影响分词结果吗?
这个例子是把文本拆成几段来分词了,被拆的句子不完整了吧!不影响分词结果吗?如果有电子邮件、日期、url等多个怎么办呢?
具体来说我是这样做的, 但是我不知道这样做对不对。
- 对于每一种要匹配的规则, 如URL, 电子邮件等, 用正则进行匹配, 并将原词替换成一个独一无二的词语, 譬如如果替换了url, 则将原词替换为#网址#, 并记录下位置。
[IN] = '我去htttp://bbs.hankcs.com上查北京在哪儿'
[OUT] = ['我去#网址#上查#地点#在哪儿', ('http://bbs.hankcs.com', '北京')]
- 对原句进行分词
[IN] = '我去#网址#上查#地点#在哪儿'
[OUT] = ['我', '去', '#', '网址', '#', '上', '查', '#', '地点', '#', '在', '哪儿']
- 对分词后的结果进行替换(用一个
iterator直接找过去, 如果遇到了#<>#的格式就进行替换就行。 替换的东西我们上一步已经进行了记录
[IN] = ['我', '去', '#', '网址', '#', '上', '查', '#', '地点', '#', '在', '哪儿']
[OUT] = ['我', '去', 'http://bbs.hankcs.com', '上', '查', '#', '北京', '#', '在', '哪儿']