
想跟大家讨论一下使用问题,如何与他们的分词模式一致?
我提取了文件中的词,使用自定义词库加入分词,文本分类的auc反而下降
感谢分享。
可以下。这个词向量的效果好不好?
多谢多谢
通过训练接口执行语料时,不知道为什么16G+的语料变成了40几M了。
请问大佬这是为什么呢?
是否和电脑配置有关呢?(本人pc为19款顶配MacBook Pro)
如图:
执行训练前的语料文件
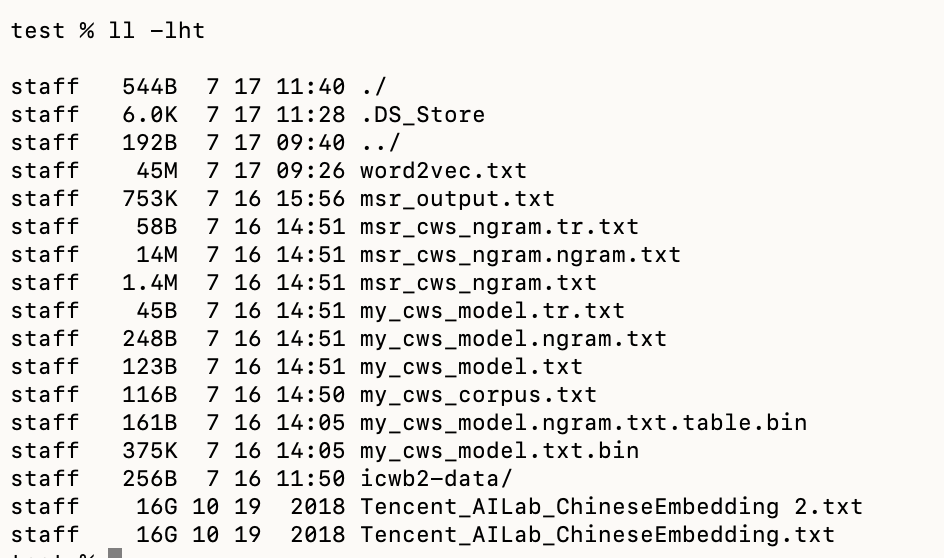
执行训练后的语料文件
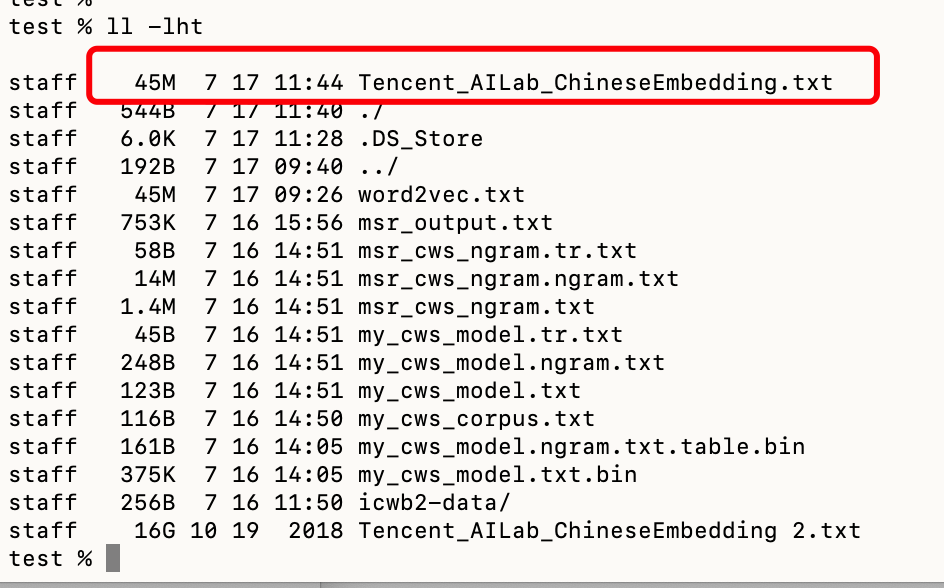
你看一下你自己的代码,感觉是重写了文件内容
我知道我测试为什么出现这个问题了。
我想问一下,大佬你用这个语料训练,跑完训练用了多久?
多谢分享
大厂就是不一样,是个数据都上G,甚至按T计算
感谢分享!
感谢分享!感谢分享!
还不错,比自己训的好不少
谢谢分享,挺不错的
谢谢分享 正好最近在找这种资料
555~我是新手,结果看了一天还没搞清楚他的语料库格式。。。。
感谢分享~试用一下
相当nice,不过这个有点大,解压完16G,我之前用过一个mini版的可以作为测试和开发环境用。回头找找发出来。
谢谢分享 
1 Like
x相当给力,感谢楼主
牛皮,感谢楼主!!!!!!