
各位大哥好,初用hanlp,最近在使用hanlp进行分词模型训练,使用TransformerTokenizer()分词器,学习率为5e-6,epoch为100,训练出来的模型,测试分词的准确率只有25%左右,请问下我应该如何调整参数,提高我的模型准确率。
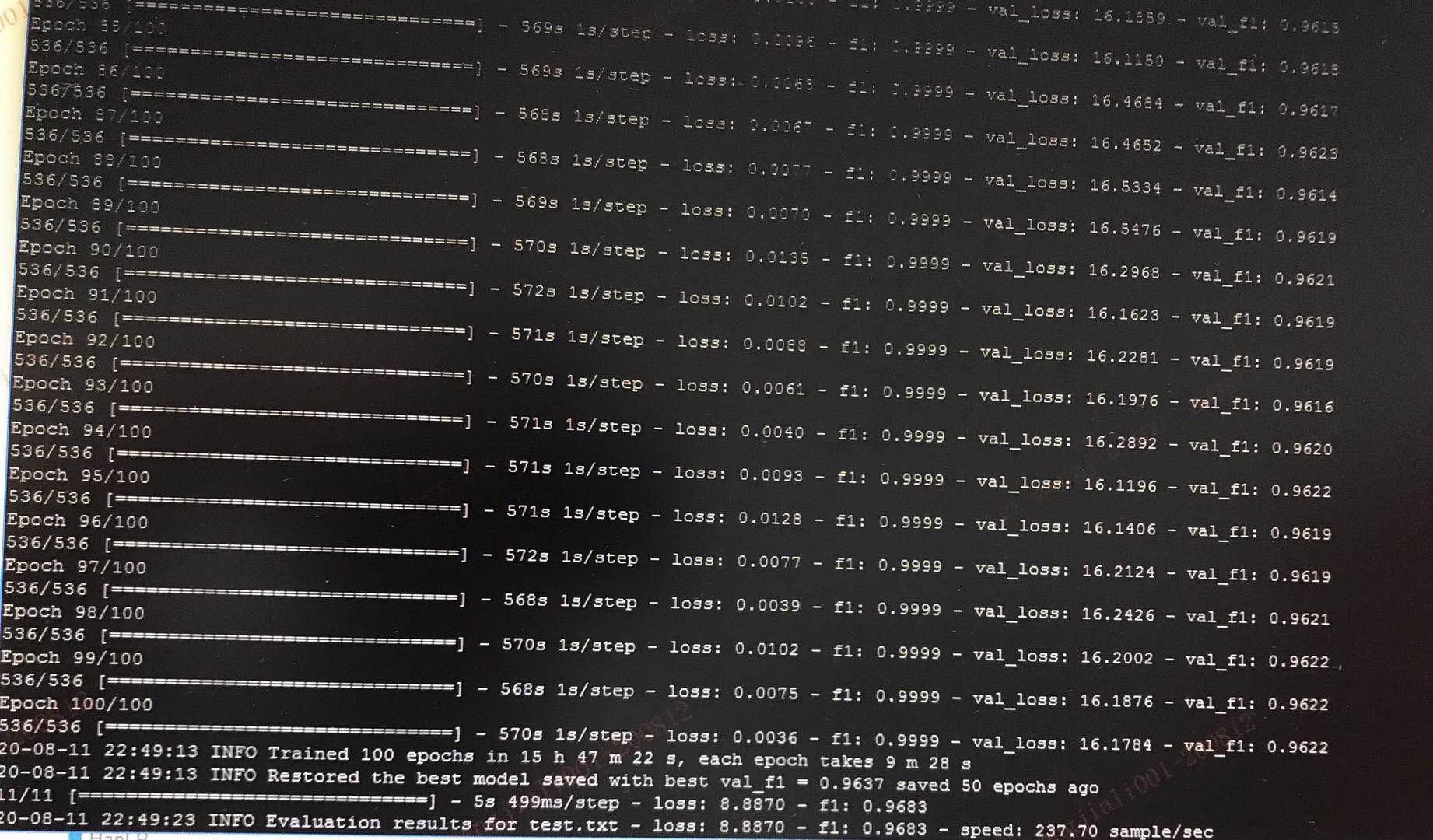
你的截图显示测试集f1为 96.83。
是的,训练出来的模型显示有96.83%,但是在使用该模型去测试一些句子分词的时候,该模型的分词效果并不好,我对比的是该模型分出来的句子和正确的句子(语料库句子)对比,大概只有25%,分出来正确的词也只有15%左右,就很纳闷,为什么会这样子呢?希望何博士可以指导一下,我想做的是粤语的分词模型。
何博士,我找到根本原因了。因为我训练的模型vocabs.json文件中的idx_to_tokens参数值比自带的模型(例如PKU_NAME_MERGED_SIX_MONTHS_CONVSEG)多了个"pad"。在利用我训练的分词模型进行分词时,txt.py文件中的Y_to_tokens此方法在生成tags时,因采取的是列表截取方式,并且是从0位截取,导致我新训练的模型生成tags列表的第一个都是"pad",故正确的tags对应字的"S B M E"都错开了一位。想问一下这是我训练的代码没写正确呢,还是本身hanlp的bug呢?
2 Likes
感谢反馈,的确是一个bug。已经修复,请升级到新版,或参考下面的补丁:
何博士,不好意思,现在才回复您,之前生病住院了。。。何博士,按照您的补丁修改了相应文件的代码后,还是会出现分词不准确的问题。但是还原代码后,我自己进行修改了一下txt.py文件,增加一个判断,tag_vocab.idx_to_token列表中有没有"pad",有就截取索引为[:len(text)],没有为[1:len(text) + 1],虽然可能会不太稳,但是已经可以满足我的需求了,哈哈。因为何博士的太高级了,我没理解到 
保重。
旧版本过年那会儿写的比较仓促,而且没有写完,没有写padding token对loss的影响,以及[CLS]的排除。如果你用了补丁的话,需要重新训练。
那是不是hanlp的预训练模型也要重新下载了?
只影响CWS,并且CWS之前没有发布Transformer预训练模型,所以不用重新下载(如果任何模型更新了,下载都是自动的)。但重新训练一下的话,可能准确率会小小地提高一些。
好的,感谢何博士的指导!