
您好,请问10.2.2节 P293 讲到文本聚类时 提到“一般而言,词频向量适合主题较多的数据集…TF-IDF适合主题较少的数据集”,不知道这个实验结论的背后有没有什么相关的解释?我在自己的数据集上也验证了这一点,但是背后的原因想不清楚,望指点~谢谢
1 Like
Hi,这是个好问题。
这个结论更多地来源于工程经验,理论依据则源于TF-IDF对特征向量的“锐化”效应以及KMeans本身的 Centroid-based 属性。
- TF-IDF以DF降低了宽泛词语的权重,这一点增加了特征向量的区分度,在多主题文档集合中尤为明显。因为当主题越多,高频词在部分主题中的分布越可能重合。比如“手机”这个词经常出现在数码和通信主题中,当文档只有数码和星座2个主题时,它是可以区分这这二个主题的。而加入通信之后,手机在数码和通信中的分布就没有区分度了。这时TF-IDF就不会那么依赖手机的词频,而是加强了某个有区分度的词语的权重,相当于“锐化”了向量。
- KMeans是个 Centroid-based的算法,对样本之间的距离非常敏感。如果两个向量距离很近,那么即便全局上它们属于不同的分布,也极有可能被划入同一个簇。参考wiki图片:
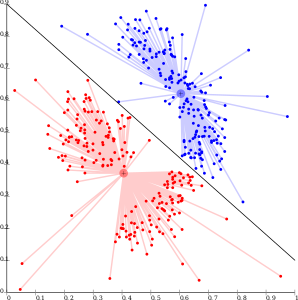
谢谢您的解答。但要是这么说的话,感觉是TF-IDF更适合主题多的数据集了,好像和书上说的正好相反,书上说:“一般而言,词频向量适合主题较多的数据集…TF-IDF适合主题较少的数据集”
很久没做聚类,的确说反了。不过这也正巧说明了这是个工程经验,理论难以解释甚至与实践相反。这也应该是当初没有展开讲的原因,可以当成一个开放问题,欢迎任何人参与讨论。
谢谢。也受您的启发,我大致思考了一下,暂时有这样的想法:如果不同主题的词汇交集比较多的时候,tf-idf应该更加合适,就像您举的例子——数码、星座、通信,锐化作用会加强更有区分度的词语。如果不同主题的词汇交集比较少,tf应该更合适,用tf-idf反而会使这些本来有区分度的词权重下降,而使本来没有区分度的词权重上升,比如您举的例子——数码、星座,“手机”本来是一个区分词,但如果很多文档都出现手机,tf-idf反而使“手机”的权重下降,适得其反了。但具体操作之前,并不知道这些文档中,不同主题的词汇的交集是不是很多,所以不能预先判定。所以,我目前的想法是,tf向量应该更适合主题词汇交集少的数据集,tf-idf更适合主题词汇交集多的数据集,而不是以主题的多少来衡量。
但对比我的数据集,确实是主题多的时候,它们的词汇交集其实很少,不同主题之间没有很大的关联度,如果这是一般情况的话,确实也就意味着一般而言,主题多的时候tf向量更合适~也与书上说的是一致的。
1 Like