
To prevent pretrained transformers from overfitting and aggressive updating, this paper proposed two regularization methods.
Smoothness-Inducing Adversarial Regularization
The main idea is forcing the model to produce similar prediction for neighboring data points.
where \mathcal{L}(\theta) is the loss function defined as
and \ell(\cdot,\cdot) is the loss function depending on the target task, \lambda_{\rm s}>0 is a tuning parameter, and \mathcal{R}_{\rm s}(\theta) is the smoothness-inducing adversarial regularizer. Here we define \mathcal{R}_{\rm s}(\theta) as
\ell_{\rm s} is chosen as the symmetrized KL-divergence, i.e.,
\tilde{x}_i is the generated neighbors of training points, serving as augmented data as shown in the following figure.
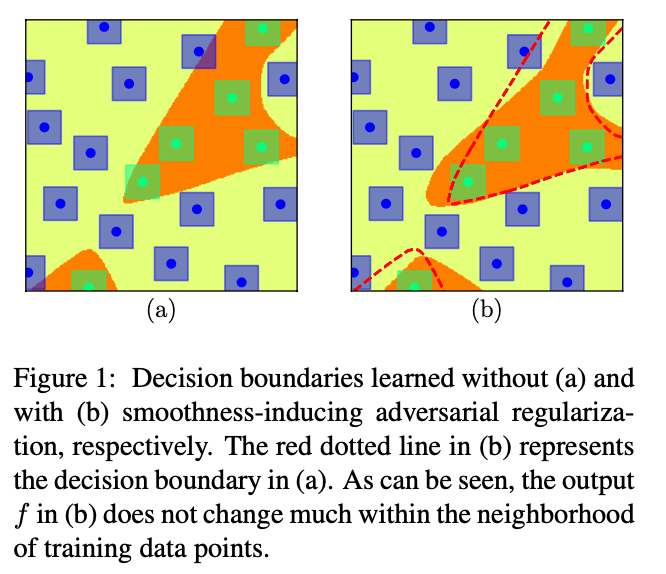
Bregman Proximal Point Optimization
It’s nothing else but a regularization term forcing the updation of parameters to be gentle.
where \mu>0 is a tuning parameter, and \mathcal{D}_{\rm Breg}(\cdot ,\cdot) is the Bregman divergence defined as
\ell_{\rm s} is the symmetrized KL-divergence mentioned above.
Results
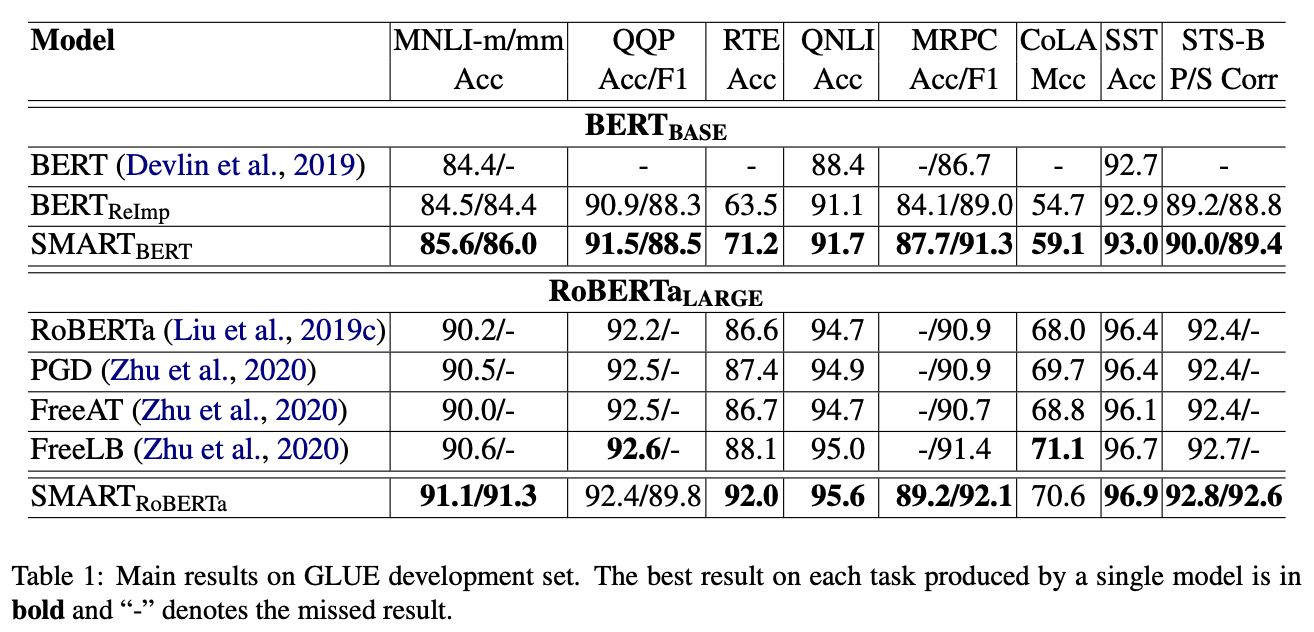
Their method consistently outperforms baseline.
Comments
This paper looks scary at the first glance as there seems to be a lot of equations. But it turns out to be easy to follow.
- 5: Transformative: This paper is likely to change our field. It should be considered for a best paper award.
- 4.5: Exciting: It changed my thinking on this topic. I would fight for it to be accepted.
- 4: Strong: I learned a lot from it. I would like to see it accepted.
- 3.5: Leaning positive: It can be accepted more or less in its current form. However, the work it describes is not particularly exciting and/or inspiring, so it will not be a big loss if people don’t see it in this conference.
- 3: Ambivalent: It has merits (e.g., it reports state-of-the-art results, the idea is nice), but there are key weaknesses (e.g., I didn’t learn much from it, evaluation is not convincing, it describes incremental work). I believe it can significantly benefit from another round of revision, but I won’t object to accepting it if my co-reviewers are willing to champion it.
- 2.5: Leaning negative: I am leaning towards rejection, but I can be persuaded if my co-reviewers think otherwise.
- 2: Mediocre: I would rather not see it in the conference.
- 1.5: Weak: I am pretty confident that it should be rejected.
- 1: Poor: I would fight to have it rejected.