
Graph encoder is a challenging block for many network designers, while many of their designs are pushing the same old buttons. This paper proposed a relatively fancy design, but still looks over-complex to me. Its complexity even makes me wonder how it was able to produce the accuracy they reported.
In a well-known GCNN like graph network, representation of a node is getting updated by its neighbors. This is not enough, people has been trying to make use of more nodes which they call ancestors, higher-order neighbors, shortest path or whatever eye-catching terms.
Similarly, this paper can be covered using one sentence: use all order K neighbors. As these neighborhood relationships are between nodes not including arc labels, they patch their approach with a conversion from labeled graph to unlabeled one, which involves removing relations and adding a line graph. However, this patch introduces twice as many nodes and doesn’t make any sense for the relations in line graph. You will quickly find this incongruity when you see the figure on their first page.
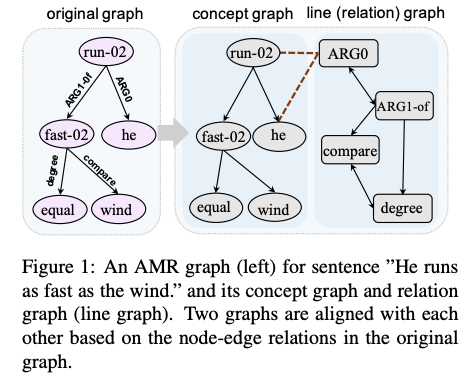
Why ARG0 has to be connected to ARG1-of? Any linguistically sounding reason other than they share the same start point? No, they are connected for the only reason that the authors want to fit their model into some unlabeled graph and line graph happens to be the “novel” one.
After this conversion, they build 3 attention mechanisms into their model:
- attention within concept graph
- attention within relation graph
- cross-attention between these two
It makes no sense why the line graph works and I’m really hoping they can provide us with a good explanation. Although this paper is well-written and reports significant results, it’s simply hard to convince me. The last criticism is that they are not releasing their code although they claim they did in their paper.
- 5: Transformative: This paper is likely to change our field. It should be considered for a best paper award.
- 4.5: Exciting: It changed my thinking on this topic. I would fight for it to be accepted.
- 4: Strong: I learned a lot from it. I would like to see it accepted.
- 3.5: Leaning positive: It can be accepted more or less in its current form. However, the work it describes is not particularly exciting and/or inspiring, so it will not be a big loss if people don’t see it in this conference.
- 3: Ambivalent: It has merits (e.g., it reports state-of-the-art results, the idea is nice), but there are key weaknesses (e.g., I didn’t learn much from it, evaluation is not convincing, it describes incremental work). I believe it can significantly benefit from another round of revision, but I won’t object to accepting it if my co-reviewers are willing to champion it.
- 2.5: Leaning negative: I am leaning towards rejection, but I can be persuaded if my co-reviewers think otherwise.
- 2: Mediocre: I would rather not see it in the conference.
- 1.5: Weak: I am pretty confident that it should be rejected.
- 1: Poor: I would fight to have it rejected.