
小白刚刚开始学习hanlp,在看示例代码的时候不太明白,请教大佬们~
首字散列其余二分的字典树,在构建字典树的过程中,将一个词拆分为多个字插入字典
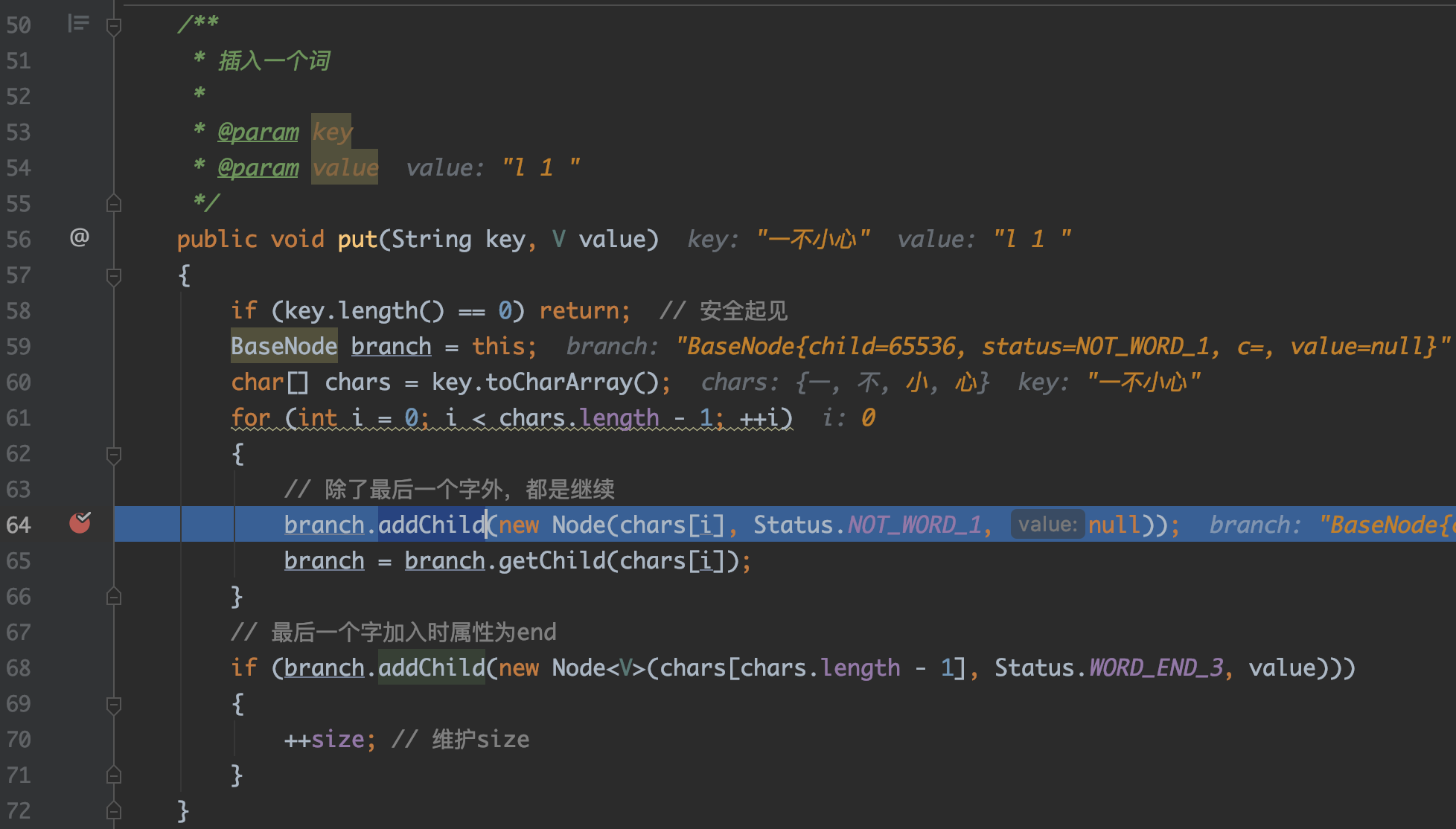
当第一个字来的时候,从代码第64行,进入BinTrie类的addChild,走首字散列的逻辑
从第二个字(非末尾)开始,同样从代码64行,进入Node类的addChild,走二分查找的逻辑
请问这里64行的代码是通过什么区分首字和非首字的,然后判断应该进哪个类的addChild的
图中代码package com.hankcs.hanlp.collection.trie.bintrie BinTrie