
学术界拆分
ctb9的拆分在学术界已有定论,根据IJCNLP 2017上Shao et. al的论文,应当做如下兼容ctb5的拆分:
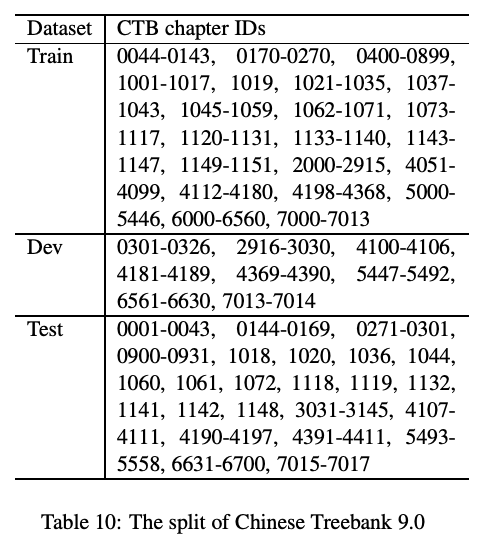
而ctb8是ctb9的子集,不难得出,将上述ctb9的每个集合取ctb8的交集,即可得出ctb8的拆分。
然而可惜的是,这份ctb9拆分遗漏了51个文件,亦即4000-4050这个区间。而且该拆分在各个领域(genre)上的分布比较不均匀。ctb9一共8个领域,分别为:
- nw 新闻
- mz 杂志
- bn 广播新闻
- bc 广播访谈
- wb 博客
- df 论坛
- sc 短信
- cs 聊天
在这些领域上,学术界拆分导致的文件数统计如下:
Shao et. al (2017) 拆分统计
| genre | train | dev | test |
|---|---|---|---|
| nw | 604(79.47%) | 25(3.29%) | 131(17.24%) |
| mz | 117(90.00%) | 0(0.00%) | 13(10.00%) |
| bn | 965(79.95%) | 122(10.11%) | 120(9.94%) |
| bc | 69(80.23%) | 9(10.47%) | 8(9.30%) |
| wb | 171(79.91%) | 22(10.28%) | 21(9.81%) |
| df | 447(79.96%) | 46(8.23%) | 66(11.81%) |
| sc | 561(80.03%) | 70(9.99%) | 70(9.99%) |
| cs | 14(77.78%) | 1(5.56%) | 3(16.67%) |
可见这份拆分在各领域上非常不均衡,如nw和mz两者的开发集接近为零,而nw和cs的测试集占比17%。
HanLP拆分
考虑到上述样本遗漏、样本不均衡以及拆分规则复杂的问题,HanLP提出如下拆分,推荐给工业界和开源界人士:
每个文件以8结尾的划入开发集,以9结尾的划入测试集,否则划入训练集。
这个简单直白的划分不仅操作简单,而且能够保证各个领域的均衡比例。该划分的统计信息如下:
| genre | train | dev | test |
|---|---|---|---|
| nw | 655(80.76%) | 78(9.62%) | 78(9.62%) |
| mz | 105(80.77%) | 13(10.00%) | 12(9.23%) |
| bn | 967(80.12%) | 120(9.94%) | 120(9.94%) |
| bc | 70(81.40%) | 8(9.30%) | 8(9.30%) |
| wb | 170(79.44%) | 22(10.28%) | 22(10.28%) |
| df | 448(80.14%) | 56(10.02%) | 55(9.84%) |
| sc | 561(80.03%) | 70(9.99%) | 70(9.99%) |
| cs | 16(88.89%) | 1(5.56%) | 1(5.56%) |
目前ctb8已经由Wake Forest University公开下载,可以视作一份开源的语料。推荐广大NLP人士采用这份数据集,以及上述推荐拆分。
HanLP将会提供开源的预处理脚本,使用该脚本能够获得完全一致的训练数据。HanLP也提供了开源训练脚本,包括超参数和随机种子。这些开源工作能够保证结果可复现,让学术造假和虚假宣传无处遁形。