
Multilingual pre-training is demonstrated to produce performance gain for MT in this TACL paper. The authors pre-train BART on 25 languages from common crawl, including 300GB English and 47 GB simplified Chinese text. These corpora are tokenized with a sentence piece model trained on all Common Crawl data that includes 0.25M subword tokens. The noise functions they use are random masking of a span and sentence permutation. A language ID is appended to the input and appended to the output so that it is capable of unsupervised MT and also being able to be fine-tuned for MT.
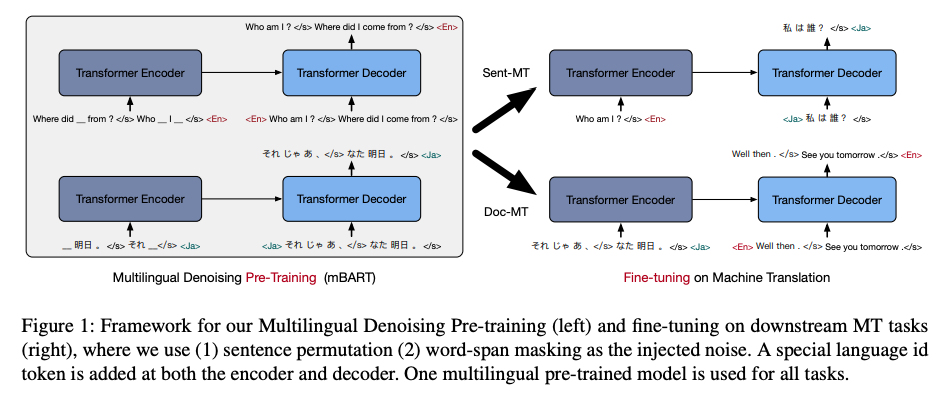
Their model, mBART, substantially outperforms SOTA non-pretraining approach and the pre-trained BART/XLM in supervised settings and unsupervised settings.
Comments
The methodology of zero-shot learning is very similar to Google NMT except that Google used LSTM. It’s good to live in this era that large scale text data can be mined with large models.
- 5: Transformative: This paper is likely to change our field. It should be considered for a best paper award.
- 4.5: Exciting: It changed my thinking on this topic. I would fight for it to be accepted.
- 4: Strong: I learned a lot from it. I would like to see it accepted.
- 3.5: Leaning positive: It can be accepted more or less in its current form. However, the work it describes is not particularly exciting and/or inspiring, so it will not be a big loss if people don’t see it in this conference.
- 3: Ambivalent: It has merits (e.g., it reports state-of-the-art results, the idea is nice), but there are key weaknesses (e.g., I didn’t learn much from it, evaluation is not convincing, it describes incremental work). I believe it can significantly benefit from another round of revision, but I won’t object to accepting it if my co-reviewers are willing to champion it.
- 2.5: Leaning negative: I am leaning towards rejection, but I can be persuaded if my co-reviewers think otherwise.
- 2: Mediocre: I would rather not see it in the conference.
- 1.5: Weak: I am pretty confident that it should be rejected.
- 1: Poor: I would fight to have it rejected.
0 投票者