
Making Decision Trees Accurate Again! This paper proposed a simple method to bring interpretability to DL models just like what decision tree does. Their method neither modifies the backbone network nor introduces any extra parameters. It only requires a tree style loss applied to the last MLP weight matrix, which is very smart.
Build Tree
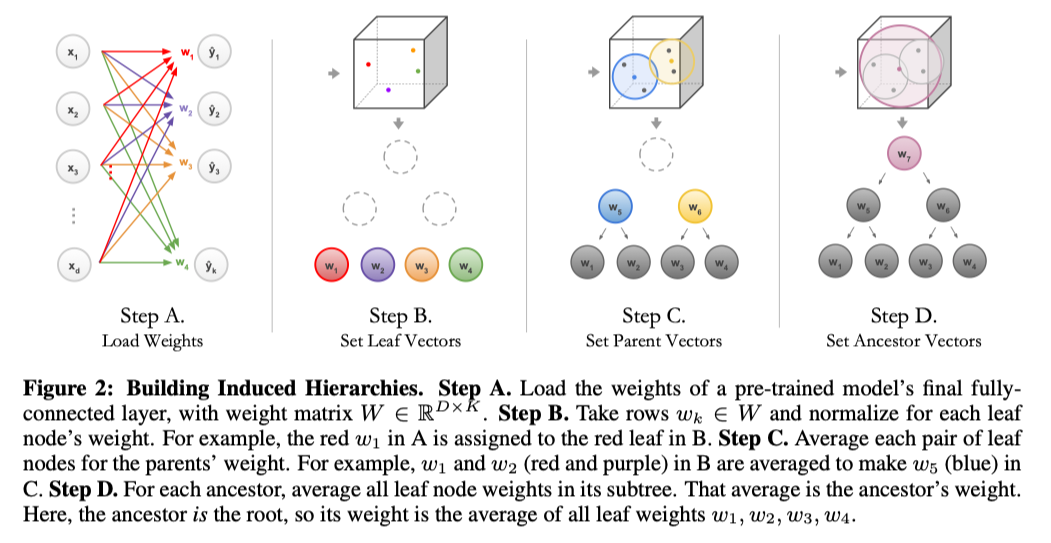
Given a pre-trained model, the weight matrix of its last MLP layer, which is a classifier, is taken out and denoted as W. Each row vector of it is denoted as w_k and assigned to a leaf node. Then these nodes are clustered using agglomerative clustering to groups. The vectors of each group is averaged and assigned to a parent node. This procedure runs iteratively till the root is created.
Inference
Denote C(i) the children for node i. Given a leaf, its class k and its path from the root P_k. The probability of reaching it is calculated in a factorized fashion. Each node i \in P_k in the path C_k(i) \in P_k \cap C(i) is denoted as p(C_k(i)|i). Then, the probability of predicting k is
Training
Their tree supervision loss is often interpolated with the original CE loss as sometimes the original accuracy cannot be replicated using only the second term.
Comments
- Very neat and smart idea.
- Section 3 should have been organized in the order above.
- What if there are more leaf nodes than inner nodes? Can we “expand” instead of clustering leaves?
- 5: Transformative: This paper is likely to change our field. It should be considered for a best paper award.
- 4.5: Exciting: It changed my thinking on this topic. I would fight for it to be accepted.
- 4: Strong: I learned a lot from it. I would like to see it accepted.
- 3.5: Leaning positive: It can be accepted more or less in its current form. However, the work it describes is not particularly exciting and/or inspiring, so it will not be a big loss if people don’t see it in this conference.
- 3: Ambivalent: It has merits (e.g., it reports state-of-the-art results, the idea is nice), but there are key weaknesses (e.g., I didn’t learn much from it, evaluation is not convincing, it describes incremental work). I believe it can significantly benefit from another round of revision, but I won’t object to accepting it if my co-reviewers are willing to champion it.
- 2.5: Leaning negative: I am leaning towards rejection, but I can be persuaded if my co-reviewers think otherwise.
- 2: Mediocre: I would rather not see it in the conference.
- 1.5: Weak: I am pretty confident that it should be rejected.
- 1: Poor: I would fight to have it rejected.
0 投票者