
This paper proposes a probabilistic model for distantly supervised relation extraction by sharing latent sentence codes between VAE and relation classifier. Their sentence codes can even be enhanced using Knowledge Base priors.
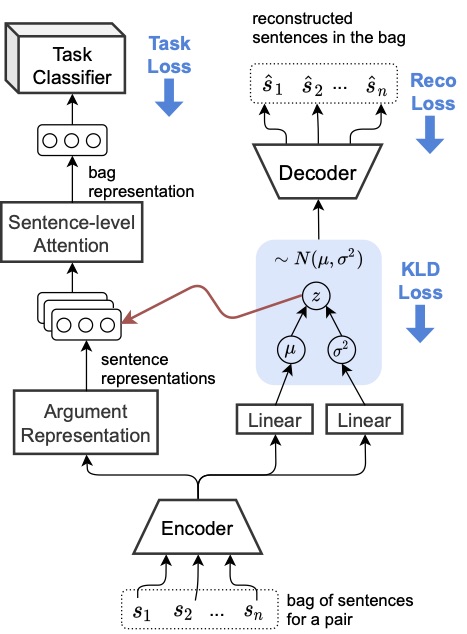
The standard ELBO is used to optimize their model.
L_\text{ELBO} = \mathbb{E}_{z \sim q_\phi(z|h)} \left[ \log(p_\theta(\mathbf{h}|\mathbf{z})) \right] \\
- D_\text{KL}\left( q_\phi(\mathbf{z}|\mathbf{h}) || p_\theta(\mathbf{z}) \right)
When no KB is available, the prior distribution of the latent code p_\theta(\mathbf{z}) is a standard Gaussian with zero mean and identity covariance \mathcal{N}(\mathbf{0}, \mathbf{I}). Otherwise TransE is used to learn entity embeddings and the prior is set to:
\def\textsc#1{\dosc#1\csod} \def\dosc#1#2\csod{{\rm #1{\small #2}}}
\def\bm#1{{\mathbf #1}}
p_\theta(\mathbf{z}) \sim \mathcal{N}(\bm{\mu}_\textsc{kb}, \mathbf{I}), \; \text{with} \; \; \bm{\mu}_\textsc{kb} = \mathbf{e}_h - \mathbf{e}_t,
\label{eq:mu_kb}
Comments
- Overall it is a smart idea. You can drop the VAE decoder at inference to speed up.
- What happens if you use a TransE trained on a different KB? Is it possible to “join” multiple KB through the prior distribution?
Rating
- 5: Transformative: This paper is likely to change our field. It should be considered for a best paper award.
- 4.5: Exciting: It changed my thinking on this topic. I would fight for it to be accepted.
- 4: Strong: I learned a lot from it. I would like to see it accepted.
- 3.5: Leaning positive: It can be accepted more or less in its current form. However, the work it describes is not particularly exciting and/or inspiring, so it will not be a big loss if people don’t see it in this conference.
- 3: Ambivalent: It has merits (e.g., it reports state-of-the-art results, the idea is nice), but there are key weaknesses (e.g., I didn’t learn much from it, evaluation is not convincing, it describes incremental work). I believe it can significantly benefit from another round of revision, but I won’t object to accepting it if my co-reviewers are willing to champion it.
- 2.5: Leaning negative: I am leaning towards rejection, but I can be persuaded if my co-reviewers think otherwise.
- 2: Mediocre: I would rather not see it in the conference.
- 1.5: Weak: I am pretty confident that it should be rejected.
- 1: Poor: I would fight to have it rejected.
0 投票者