
This paper presents a surprisingly effective pipeline that outperforms SOTA joint models. Their pipeline predicts entity first then uses predicted entity type as markers and fed each pair of marked spans into a relation model later. This pipeline involves two separately fine-tuned PLMs and the relation model requires encoding of every possible pair of spans. To mitigate the latency issue, they proposed an approximation method which removes the attention of markers from tokens such that the encodings of tokens can be reused across all pairs.
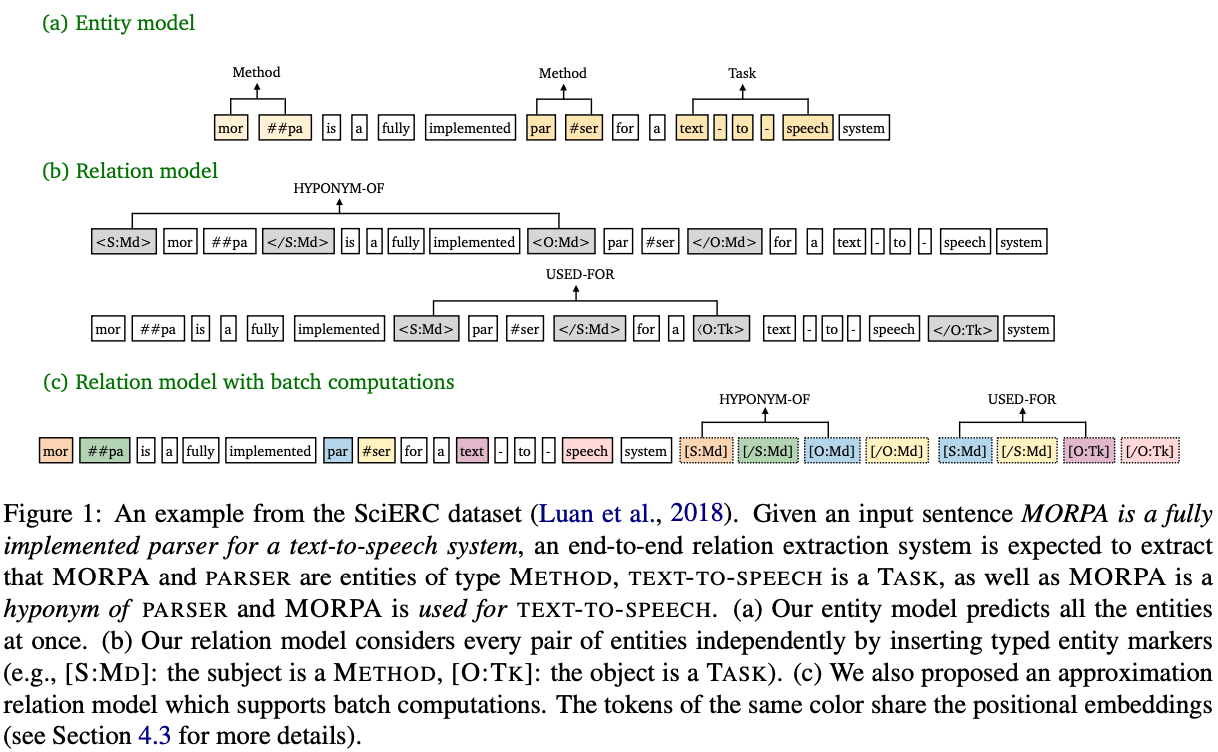
Comments
- Very simple approach but very surprisingly good performance.
- It aligns with some research findings that different task needs different features so MTL is not the silver bullet.
- Their approximation is very clever.
- The section of trying to solve error propagation is interesting too.
Rating
- 5: Transformative: This paper is likely to change our field. It should be considered for a best paper award.
- 4.5: Exciting: It changed my thinking on this topic. I would fight for it to be accepted.
- 4: Strong: I learned a lot from it. I would like to see it accepted.
- 3.5: Leaning positive: It can be accepted more or less in its current form. However, the work it describes is not particularly exciting and/or inspiring, so it will not be a big loss if people don’t see it in this conference.
- 3: Ambivalent: It has merits (e.g., it reports state-of-the-art results, the idea is nice), but there are key weaknesses (e.g., I didn’t learn much from it, evaluation is not convincing, it describes incremental work). I believe it can significantly benefit from another round of revision, but I won’t object to accepting it if my co-reviewers are willing to champion it.
- 2.5: Leaning negative: I am leaning towards rejection, but I can be persuaded if my co-reviewers think otherwise.
- 2: Mediocre: I would rather not see it in the conference.
- 1.5: Weak: I am pretty confident that it should be rejected.
- 1: Poor: I would fight to have it rejected.
0 投票者