
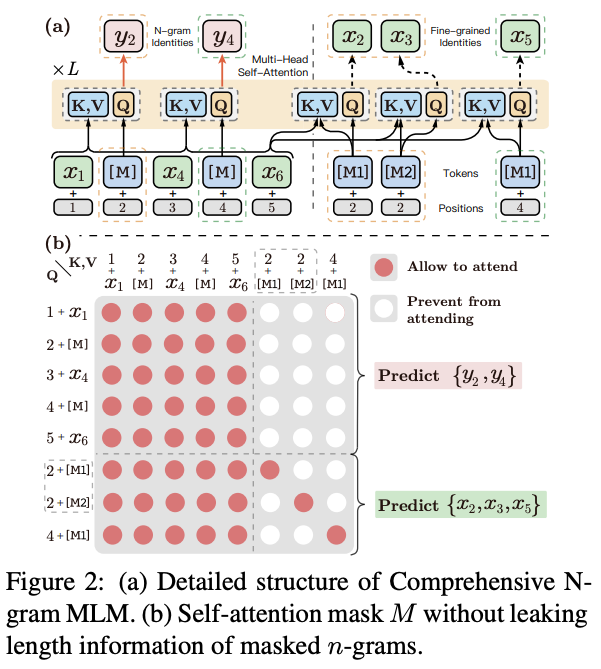
This paper incorporates ngram information into MLM pre-training and achieved new SOTA on GLUE benchmark. They argue that conventional whole word masking leaks the length information and leads to sub-optimal perforance. Similar to the denoising objective of BART, they replace a whole ngram with a single MASK and predicts the sub-word sequence. They furthur let the model predict the ngram id. These mix-grained predictions are enabled through carefully masked attention.
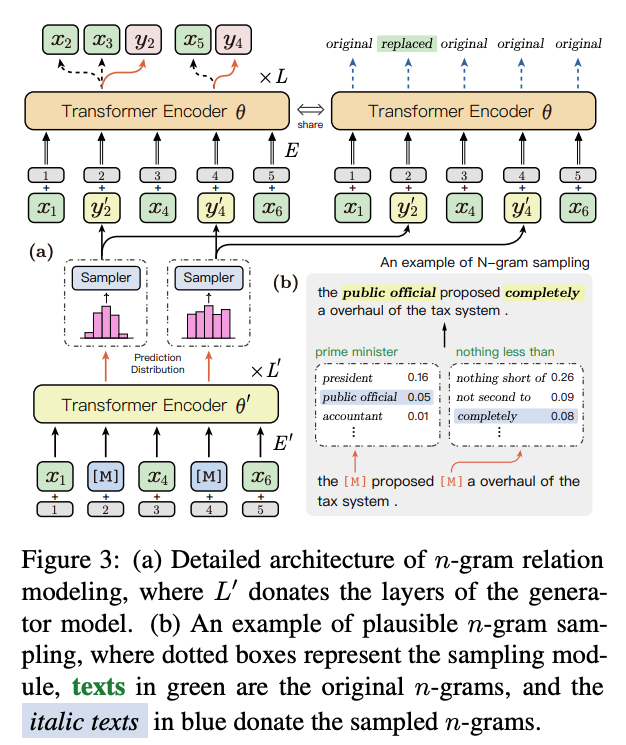
To mitigate the discrepancy between training and inference caused by the MASK, they jointly pre-train a small ML generator model to sample plausible ngrams.
Comments
- The mix-grained idea is quite novel.
- The masking idea is similar to denoising but still quite novel. It mitigates discrepancy too.
Rating
- 5: Transformative: This paper is likely to change our field. It should be considered for a best paper award.
- 4.5: Exciting: It changed my thinking on this topic. I would fight for it to be accepted.
- 4: Strong: I learned a lot from it. I would like to see it accepted.
- 3.5: Leaning positive: It can be accepted more or less in its current form. However, the work it describes is not particularly exciting and/or inspiring, so it will not be a big loss if people don’t see it in this conference.
- 3: Ambivalent: It has merits (e.g., it reports state-of-the-art results, the idea is nice), but there are key weaknesses (e.g., I didn’t learn much from it, evaluation is not convincing, it describes incremental work). I believe it can significantly benefit from another round of revision, but I won’t object to accepting it if my co-reviewers are willing to champion it.
- 2.5: Leaning negative: I am leaning towards rejection, but I can be persuaded if my co-reviewers think otherwise.
- 2: Mediocre: I would rather not see it in the conference.
- 1.5: Weak: I am pretty confident that it should be rejected.
- 1: Poor: I would fight to have it rejected.
0 投票者