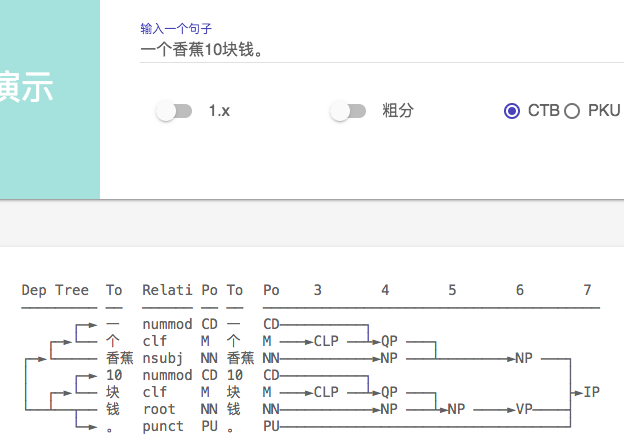
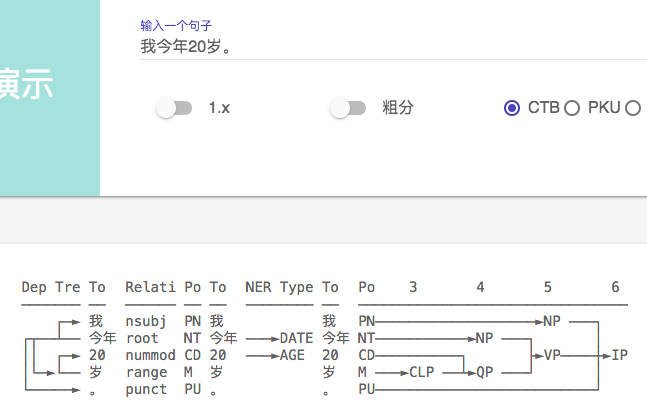
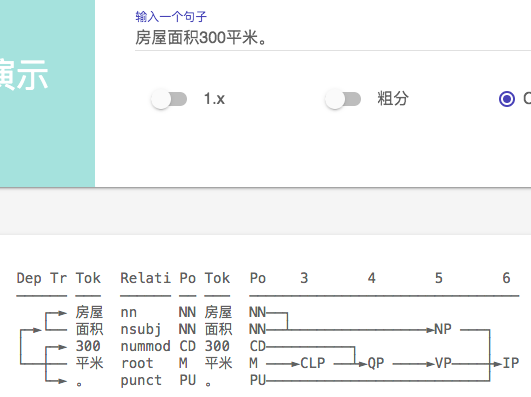
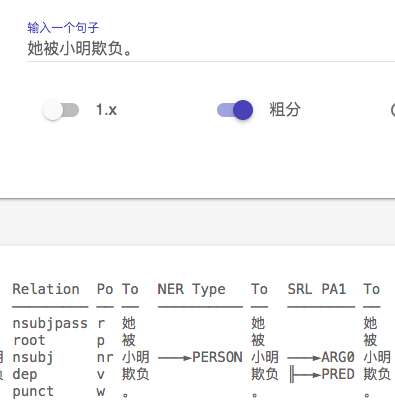
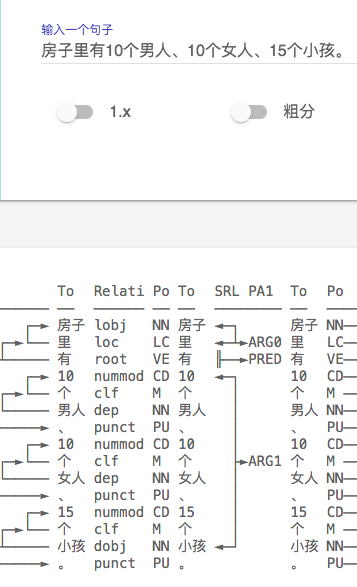
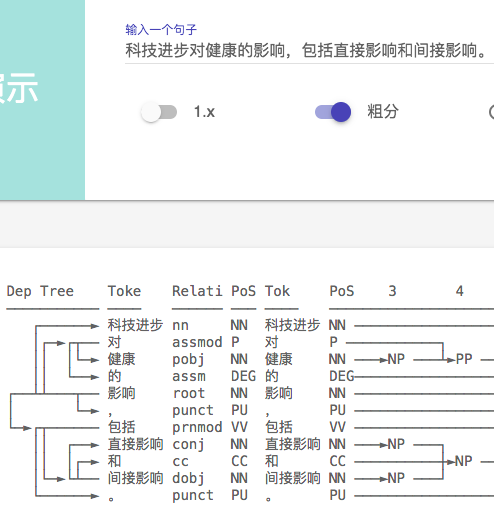
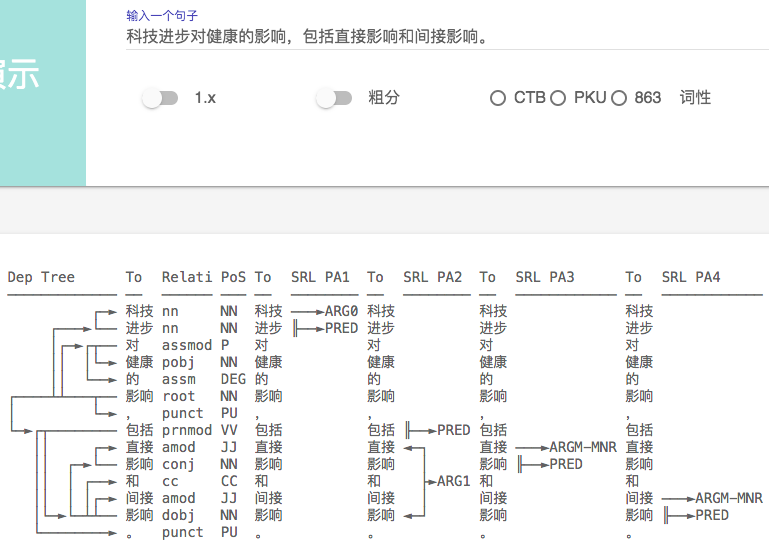
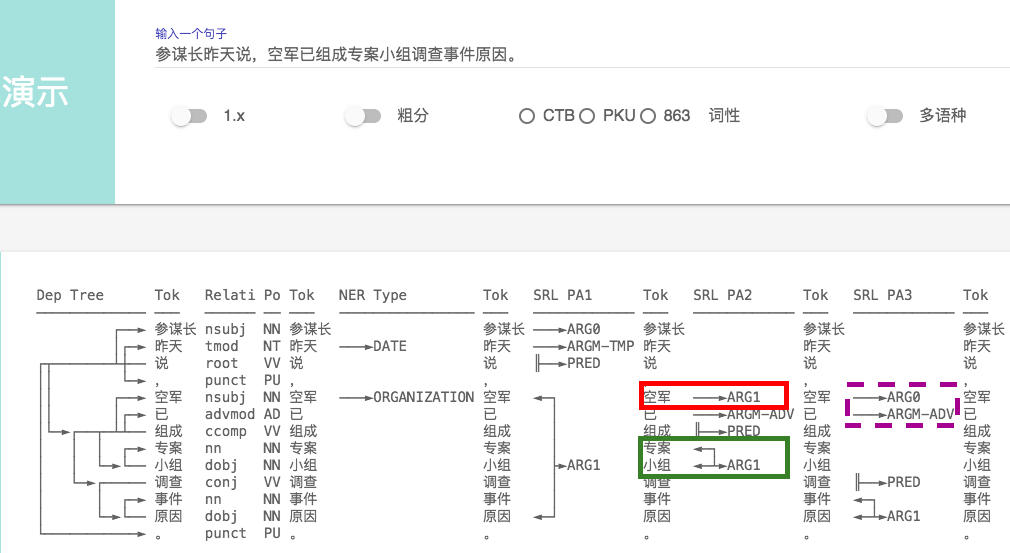
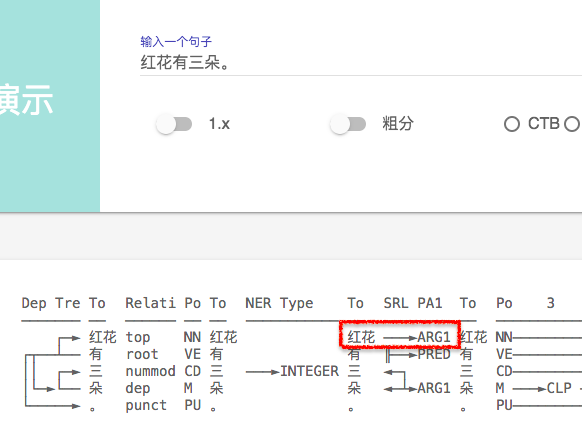
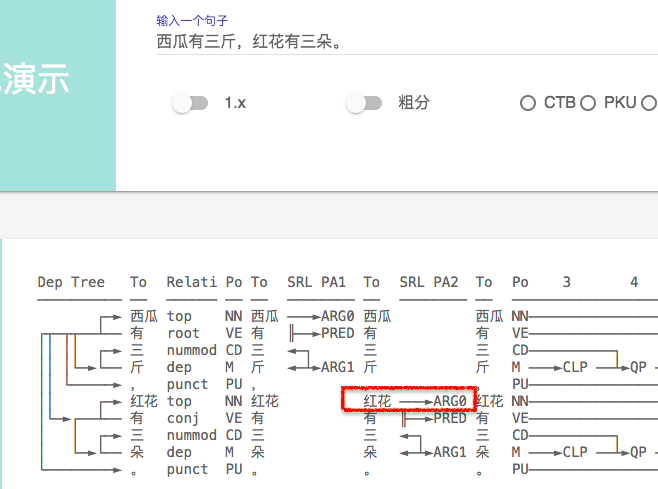
首先说说最近的使用感受,2.1在分词上的准确率已经很高了,很难挑出太大的毛病,这个要大大的
比较了https://hanlp.hankcs.com/docs/api/hanlp/pretrained/mtl.html 上列出的几个模型,感觉效果最好的还是
**hanlp.pretrained.mtl.CLOSE_TOK_POS_NER_SRL_DEP_SDP_CON_ELECTRA_BASE_ZH**
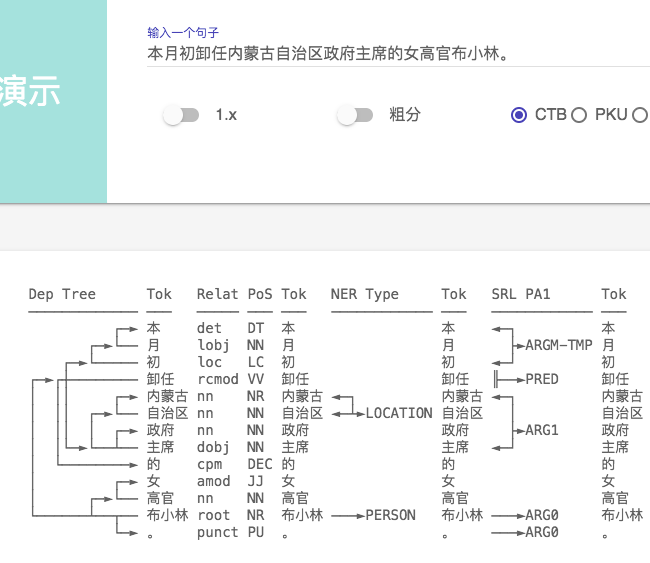
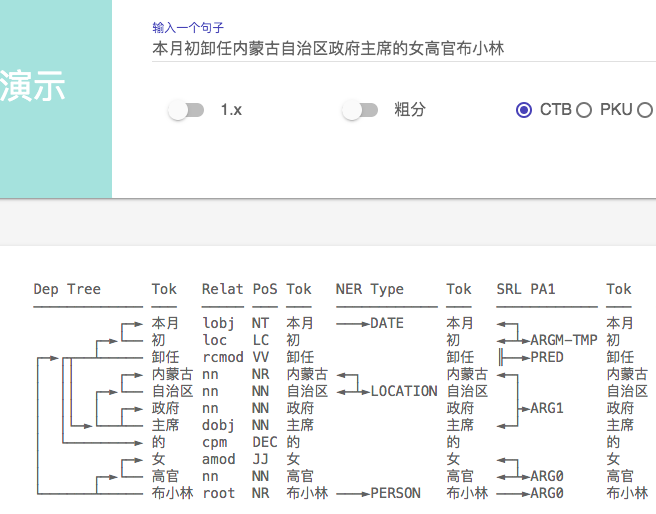
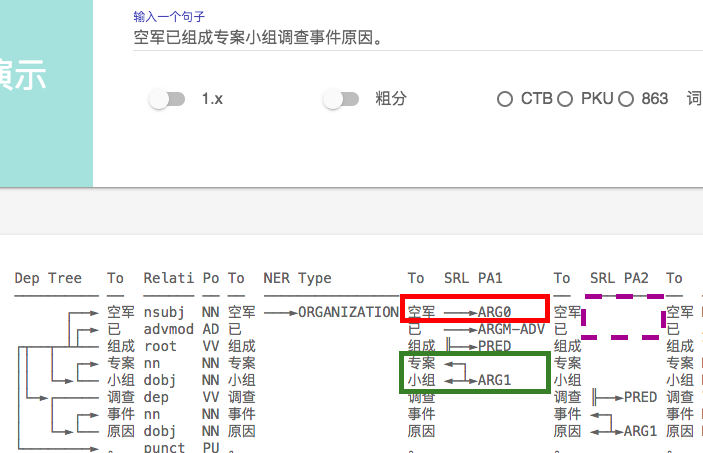
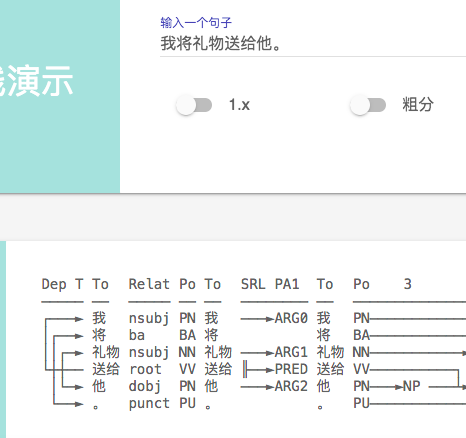
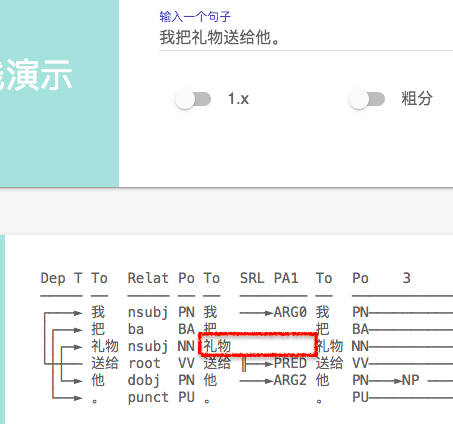
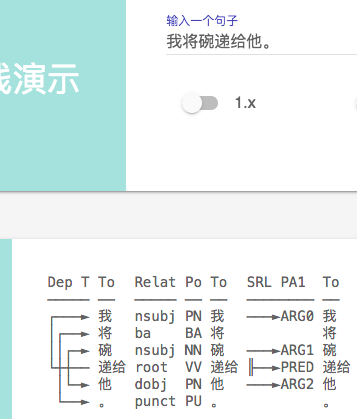
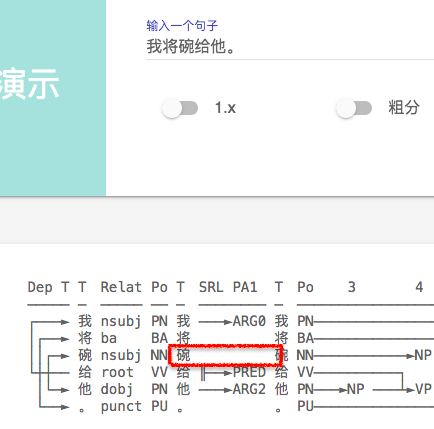
下面进入找茬时间
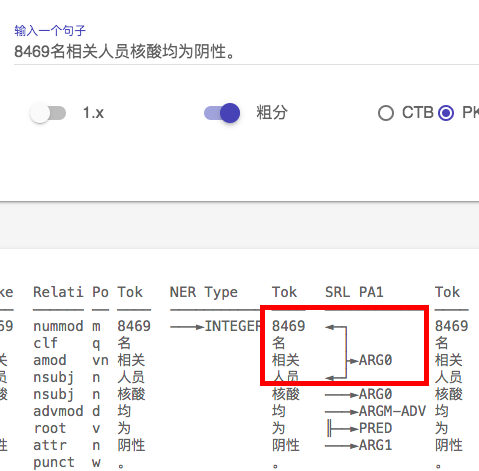
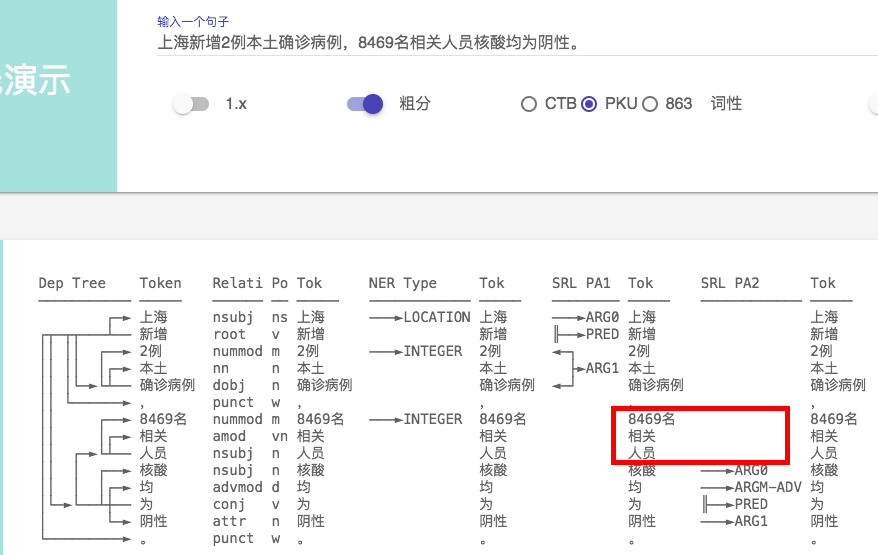
1、SRL 标记错误 ,同样一句话, 加了个句号 ARG0 发生了 飘移(句号被标为ARG0, 显然是错误)