
12章的DemoTrainParser,第一行
public static String CTB_ROOT = TestUtility.ensureTestData(“ctb8.0-dep”, “http://file.hankcs.com/corpus/ctb8.0-dep.zip”);
库的名字叫“TextUtility”,没有找到相应的class。
一个是官方下载的1.7.5的库中的相关class名叫“TextUtility”,二是官方的这个class里根本没有“ensureTestData”这个函数。
希望作者能给解决一下。。
错,TextUtility和TestUtility是两个东西。
错,这个函数在这里。
这本书写了一年多,代码在GitHub上跑得很好,感觉你理解错了。
欢迎继续提问题,同时为了避免误导他人,请编辑你的帖子。
谢谢作者大佬,原帖已经编辑过。
但还是没有解决问题,我本地的环境是下载了你的hanlp-1.7.5.jar(用maven配置也是只有这个jar),然后自己下载了data。
但是书上配套代码都要你Hanlp/src/test/下面的文件,这个test/里面的文件是另一个库还是什么?这个test/下面的文件命名和1.7.5.jar很像,但是里面有很多1.7.5.jar没有的文件,导致书上配套demo在只配置了1.7.5.jar的情况下根本跑不通,而这个test/在本地的配置无论是在github官网还是书上都没有找到。
你应该clone GitHub仓库而不是仅仅下载jar,第一章有说“所以还推荐读者去 GitHub 上创建分支(fork)并
克隆(clone)一份源码”。test文件夹是软件开发习俗的测试代码,本书代码依赖一部分测试代码,并且希望与核心代码同步更新所以放到了test目录,所以你不能脱离test去运行配套代码。项目的构建工具链是maven,如果你用jetbrain之类的IDE导入工程会自动帮你配置。作为软件工程师,这些都是基本常识。
已解决问题,谢谢作者大佬
有没有 Python 版本的代码,我看书中大部分都是 Java 代码,不懂 Java 
这不就是了:https://github.com/hankcs/pyhanlp/tree/master/tests/book
前言有说这是Python+Java双语版。主项目用Java所以Java多一些,但API都支持Python。
好的,谢谢,大神请教个问题,对于留言出现违禁词,那种算法判断更合适点,决策树吗?
违禁词没有规律,不适合机器学习,用第二章介绍的AC自动机之类匹配就行了。微博好像就是这么干的,经常误杀。追求精确可以先分词再用双数组字典树过滤。
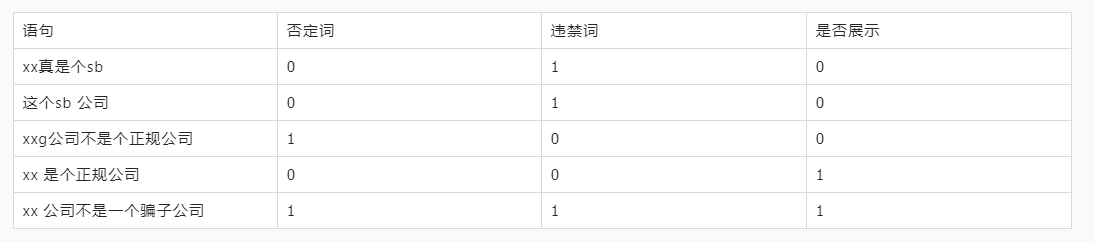
我觉得没有必要。