
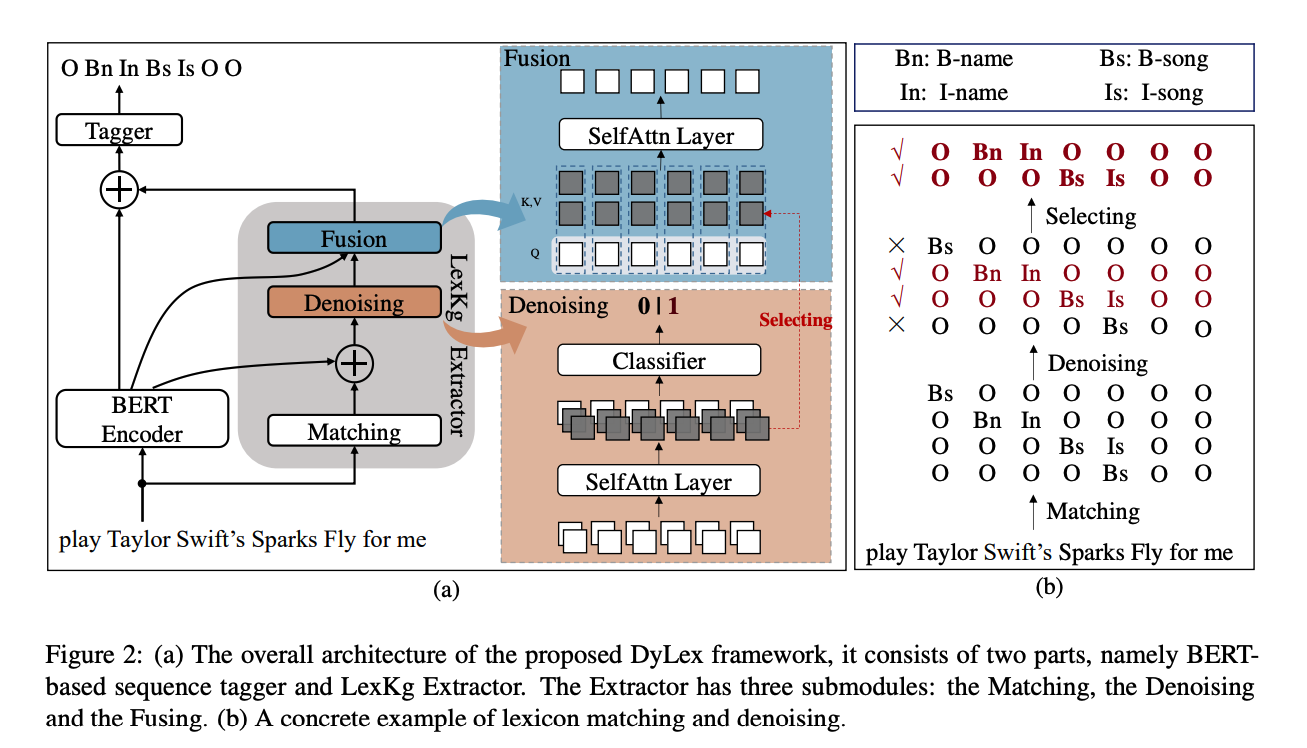
This paper proposes to model the tag sequence of matched words for dynamic integration with extern lexicon. Their method handles each matched words separately by filling unmatched ones with O tag. These sequence tags are filtered and attended by using BERT embeddings as a query.
Comments
- Overall idea is good.
- The trie matching in algorithm 1 is not efficient at all.
- In table 8, hard filtering outperforms soft filtering significantly. Will hard filtering be much slower since you’ll need to remove bad sequences from the batch on CPU?
- For these works that integrate lexicons, I’m always curious about the baseline performance of max-prefix-matching. At least for NER, max-prefix-matching introduces very low noise.
Rating
- 5: Transformative: This paper is likely to change our field. It should be considered for a best paper award.
- 4.5: Exciting: It changed my thinking on this topic. I would fight for it to be accepted.
- 4: Strong: I learned a lot from it. I would like to see it accepted.
- 3.5: Leaning positive: It can be accepted more or less in its current form. However, the work it describes is not particularly exciting and/or inspiring, so it will not be a big loss if people don’t see it in this conference.
- 3: Ambivalent: It has merits (e.g., it reports state-of-the-art results, the idea is nice), but there are key weaknesses (e.g., I didn’t learn much from it, evaluation is not convincing, it describes incremental work). I believe it can significantly benefit from another round of revision, but I won’t object to accepting it if my co-reviewers are willing to champion it.
- 2.5: Leaning negative: I am leaning towards rejection, but I can be persuaded if my co-reviewers think otherwise.
- 2: Mediocre: I would rather not see it in the conference.
- 1.5: Weak: I am pretty confident that it should be rejected.
- 1: Poor: I would fight to have it rejected.
0 投票人