
根据最早做这个数据集的Named Entity Recognition with Bilingual Constraints制定的划分标准:
This corpus includes about 400 document pairs (chtb 0001-0325, ectb 1001-1078). We used odd-numbered documents as development data and even-numbered documents as test data. We used all other portions of the named entity annotated corpus as training data for the monolingual systems …
In this paper, we selected the four most common named entity types, i.e., PER (Person), LOC (Location), ORG (Organization) and GPE (Geo-Political Entities).
再去掉EMPTY这种无意义的句子,处理得到的数据集统计信息如下:
| Split | Documents | Sentences | Tokens | Characters | Entities |
|---|---|---|---|---|---|
| trn | 667 | 15589 | 313513 | 491228 | 13372 |
| dev | 202 | 4303 | 123699 | 200526 | 6954 |
| tst | 200 | 4346 | 127854 | 208042 | 7684 |
TENER版本
与TENER: Adapting Transformer Encoder for Named Entity Recognition相比,大致是类似的。
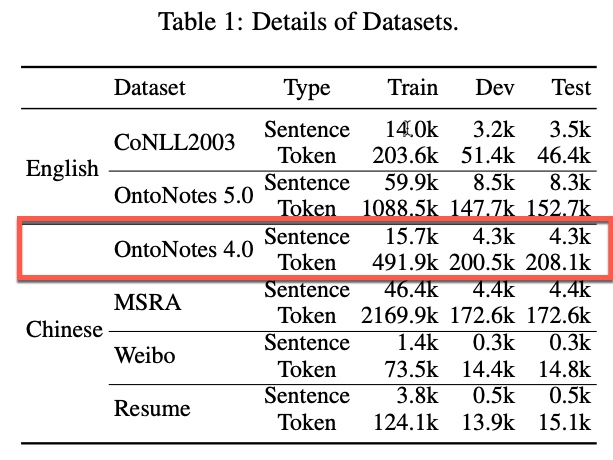
上表的Token其实指的是Character。
Glyce版本
| Split | Documents | Sentences | Characters | Entities |
|---|---|---|---|---|
| trn | - | 15724 | 491903 | 13372 |
| dev | - | 4301 | 200505 | 6950 |
| tst | - | 4346 | 208066 | 7684 |
该版本存在的错误是,误将xml中的E_OFF作为了文本。比如原始xml为:
之后 推出 通讯 软体 <ENAMEX TYPE="PRODUCT" E_OFF="1">8d call</ENAMEX> , 更 一举 拿下 全球 <ENAMEX TYPE="CARDINAL">百万</ENAMEX> 名 会员 ; <ENAMEX TYPE="DATE">九八年</ENAMEX> 针对 电子 商务 成立 即时 竞标 的 购物 网站 —— <ENAMEX TYPE="ORG">CoolBid 酷必得</ENAMEX> , 每 季 平均 营业额 为 <ENAMEX TYPE="CARDINAL">六千万</ENAMEX> , 会员 更 高 达 <ENAMEX TYPE="CARDINAL">十万多</ENAMEX> 人 。
他们预处理出来的结果是:
之后推出通讯软体TYPE=\"PRODUCT\"E_OFF=\"1\">8dcall,更一举拿下全球百万名会员;九八年针对电子商务成立即时竞标的购物网站——CoolBid酷必得,每季平均营业额为六千万,会员更高达十万多人。
另外,我对比了我的数据与他们的数据,发现他们额外地将( 完 )也去掉了。