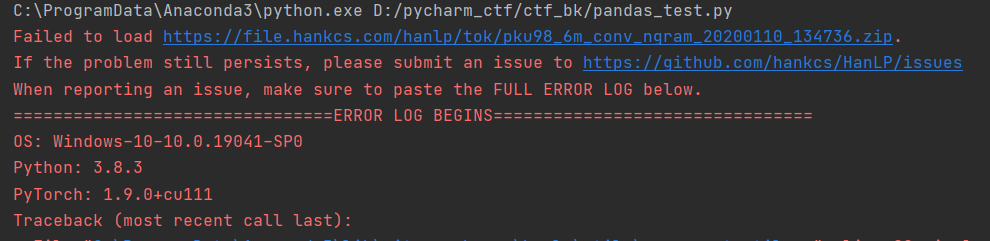
如题
import hanlp
tokenizer = hanlp.load(‘PKU_NAME_MERGED_SIX_MONTHS_CONVSEG’)
运行报错
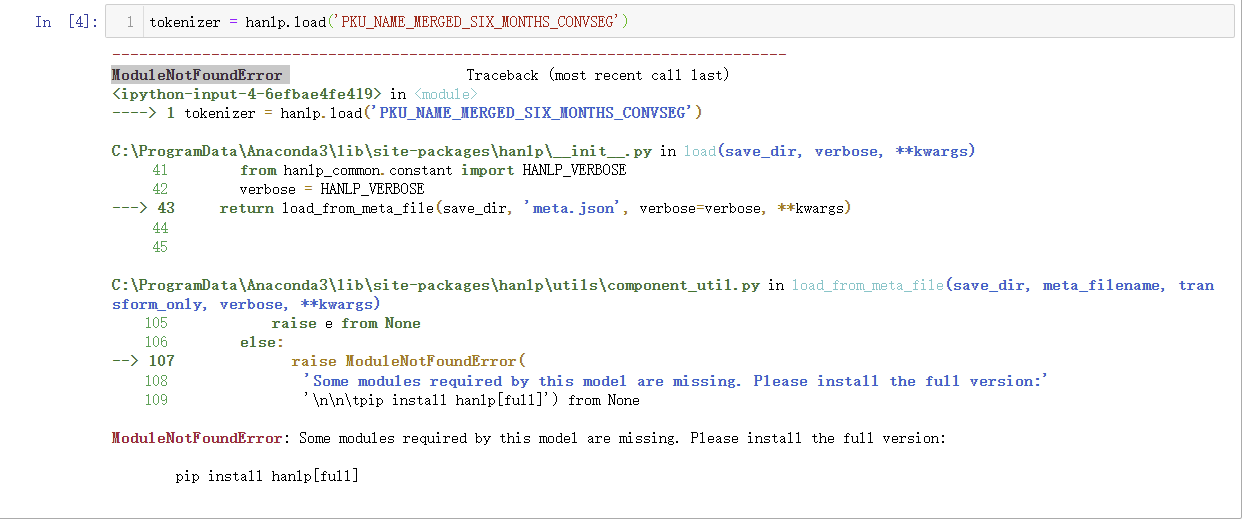
按照提示pip 安装成功后,仍然报错

如题
import hanlp
tokenizer = hanlp.load(‘PKU_NAME_MERGED_SIX_MONTHS_CONVSEG’)
运行报错
按照提示pip 安装成功后,仍然报错
感谢反馈,已经修复:
另外,建议使用以LARGE开头的模型。这些小语料库模型是2.0测试用的,效果不如大语料库。