
为啥运行书上第8章 ‘demo_role_tag_nr’ 代码时出现乱码了呢?其实先前也出现过乱码的情况,自己查了查感觉应该是调试模式那块乱码了,最后打印的结果没有乱码。
把相应的缓存nr.ngram.txt.bin和nr.txt.bin删除试试。
谢谢您的帮助,但是还是没有解决这个问题,不太清楚是不是我电脑的原因
可能是JVM的stdout输出pipe到Python时发生了编码错误,你可以排查下问题:
from jpype import *
startJVM(getDefaultJVMPath(), "-ea")
java.lang.System.out.println("中文")
1 Like
我按您说的在cmd里面进入python运行了一下,没有乱码。然后在pycharm运行的时候乱码了。早上也尝试在 println(“中文”) 里面添加 enconding=“utf-8”、"gbk"那些编码方式试了试,但是还是乱码。
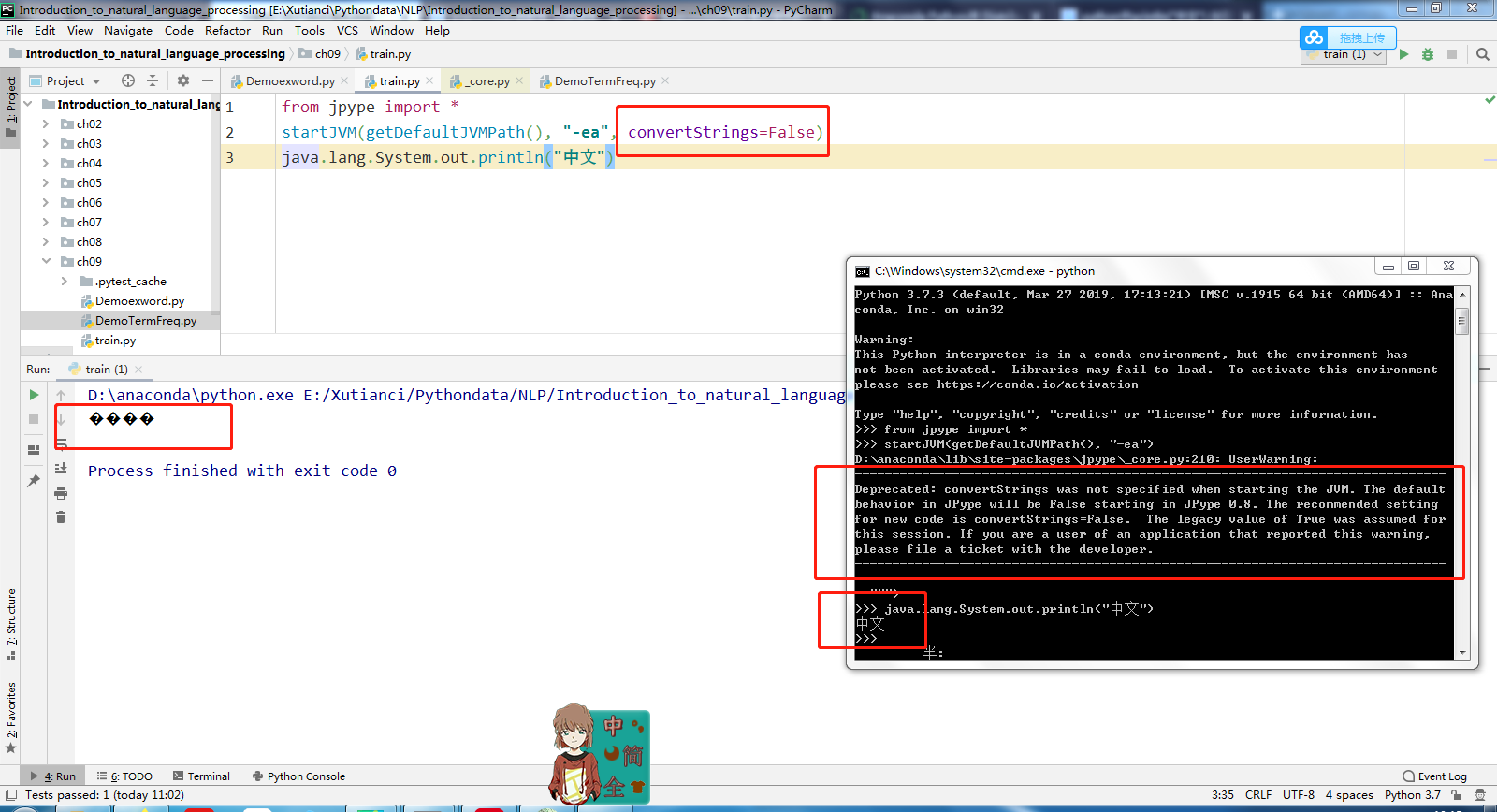
你的Pycharm要设置utf-8:
1 Like

你好,我也遇到了相同问题,你可以说说具体如何解决吗
老师,我用这个方法解决不了,还是乱码
Windows需要设置编码的地方太多了,请咨询Windows专家,或者早日用Linux。
作者先生您好! 百度各种设置 编码和字体都试了还是不行,奇怪的是一部分是乱码一部分是正常汉字 在python打印的是汉字 但是调用接口里面打印的还是乱码 所以会不会是封装的地方哪可以改进啊,您看这样的 hello_word.py 在cmd中运行是可以的(我看前面的人发的错误了 也试了还是不行)
1:[����, ����ά]
2:[]
3:[��]
4:[��, �ͷ�]
5:[����Ա]
6:[]
7:[]
8:[ ]
[王国维/nr, 和/cc, 服务员/nnt]
终于不乱码了 全部设置成System Default:GBK 就可以了 但是如果选择了run in python console 还是会有乱码 如果不选这个选项是没有乱码的 可能需要继续多试吧
Global encoding 和project encoding 都改成UTF-8之后 无论是否选中run in python consloe "utility.py demo_dat_segment.py 都可以正常显示中文 只有hello_word.py 是部分乱码部分正常显示 原因我觉得是因为java代码的缘故 希望作者先生有时间可以在window上测一下代码 因为不是所有的人都有条件换linux的
我也是乱码
设置file code为GKB解决
我发现pyhanlp很容易报utf-8的错,有时候txt文件用notpad++存为utf-8格式就报错,用UltraEdit存成utf-8就不报错。
同样的中文.txt文件,有时候即使用UltraEdit存成utf-8,仍然报utf-8的错,比如在去除停用词的程序段里报错,但在其他程序段里,就不报错,比如,分词,自定义词典
乱码底层原理是什么 