最初通过问卷调查 【投票】HanLP2.1的细分标准是否不够细? 发现75%的用户对HanLP的细分标准表示满意,剩下的25%统一觉得细分标准有点粗。另外,也有AMR用户和SRL用户表示相应模型对否定句式的处理不佳:
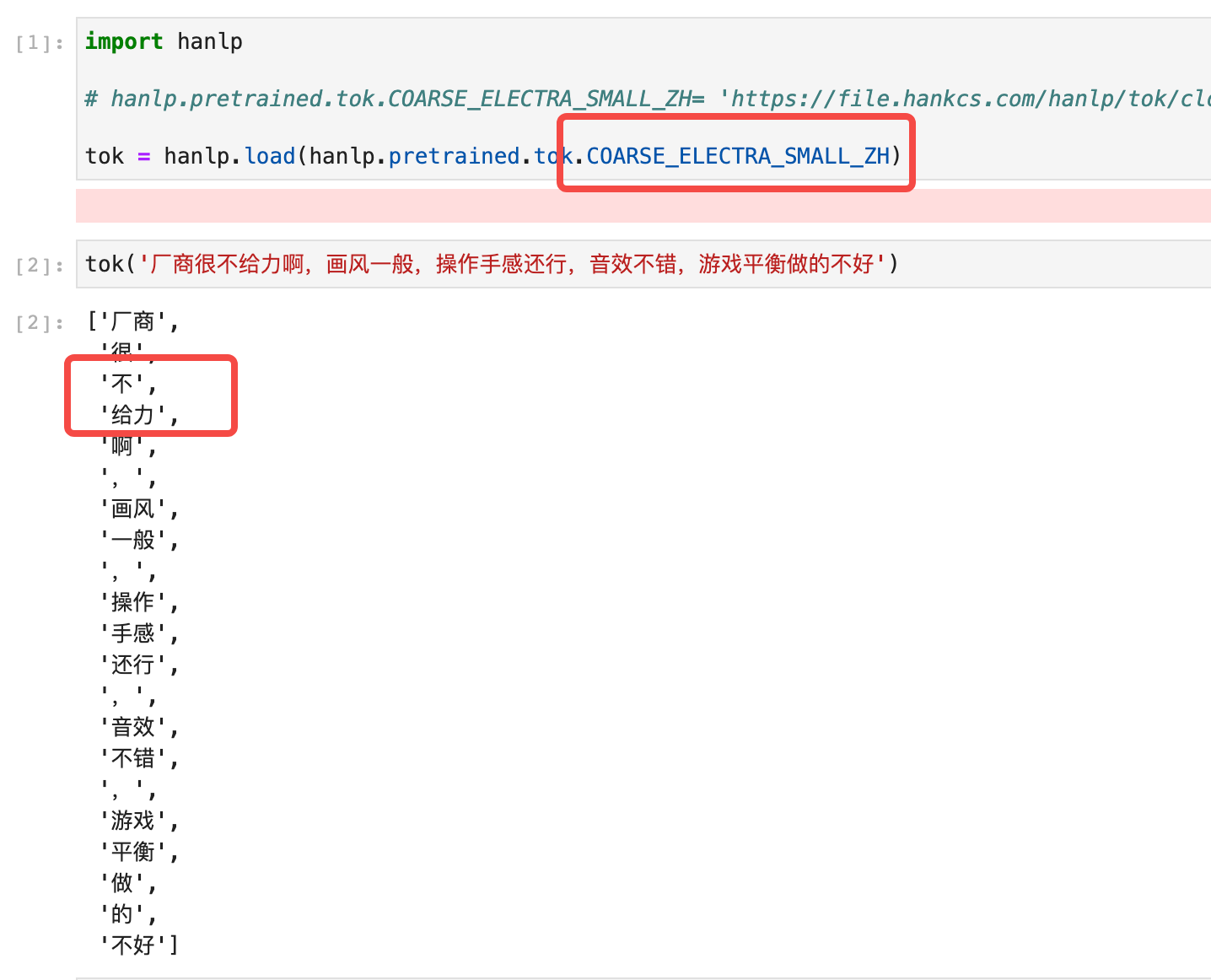
经过调查,都与细分模型的标准有关。为此,我们组织人力对内部1亿字的语料库进行了校对。分别以CTB和MSR两套标准作为细分和粗分的参考,对语料库中不规范的样本进行校正。在校正后的语料上,我们训练并发布了small体积的分词模型,并且取得了可喜的准确率提升:
| 粗分F1 | 细分F1 | |
|---|---|---|
| 旧版 | 96.92 | 97.42 |
| 新版 | 98.30 | 98.11 |
从此,HanLP的分词标准将以此次更新为基石。MTL模型正在训练中,预计一周后和线上restful服务同步更新。
最后,感谢广大用户和HanLP一起追求最专业最先进的NLP技术。