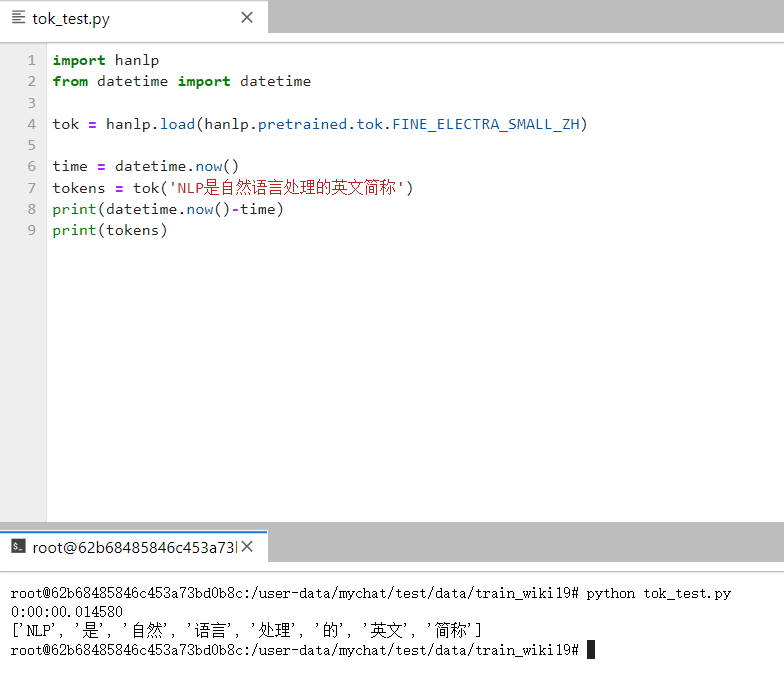
这是主机的:(windows 10, i7-9750H,GTX-1650,4g显存,16g内存)
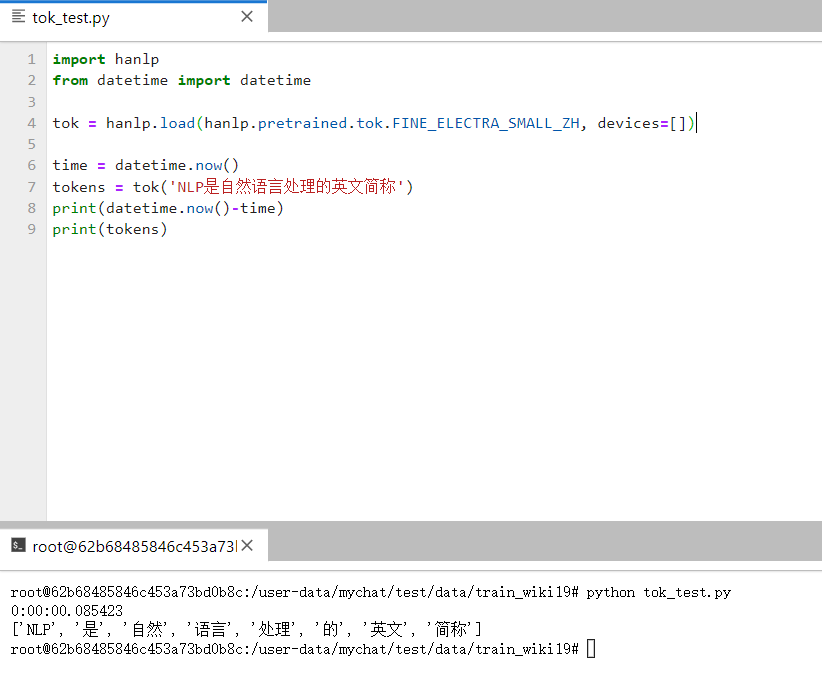
这是虚拟机的:(debian 11,8个处理器,8g内存)
我从我的训练集中又取了一些数据,二者的计算速度差了数十倍,主机的运算速度在2s左右,而虚拟机的运算速度基本都在0.1秒以内
显然我的显卡没有虚拟化,虚拟机是无法使用gpu的,hanlp的分词模型在虚拟机上是用cpu运行的。为什么虚拟机的cpu反而比主机的gpu更快?是因为分词模型较小吗?
然后,如果对于分词模型cpu真的比gpu更快,为了追求更快的分词速度,我应该需要使用cpu运行分词模型。如果对于多个句子并行分词,cpu还会比gpu更快吗?
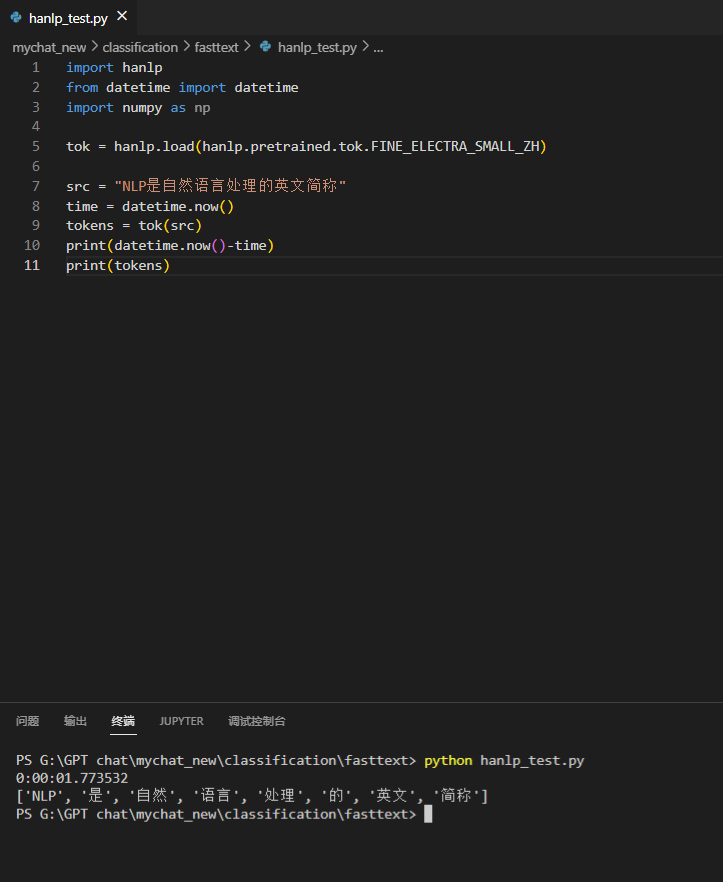
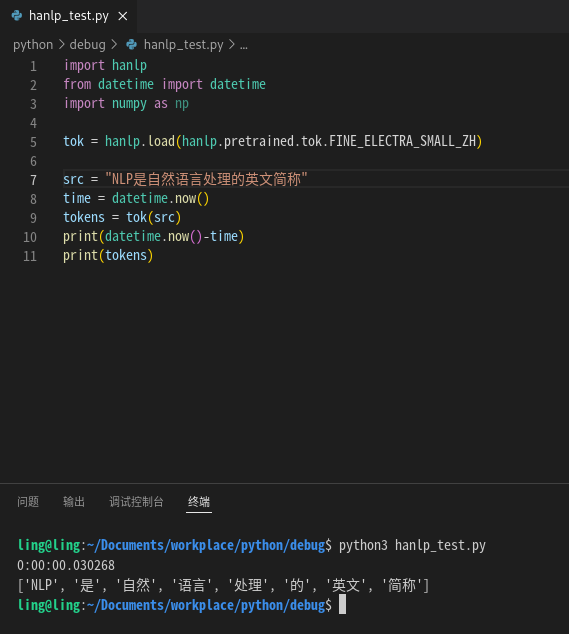
 之后我又在算力平台的实例上测试了一遍,配置是RTX3090(24g显存),使用gpu的速度:
之后我又在算力平台的实例上测试了一遍,配置是RTX3090(24g显存),使用gpu的速度: