
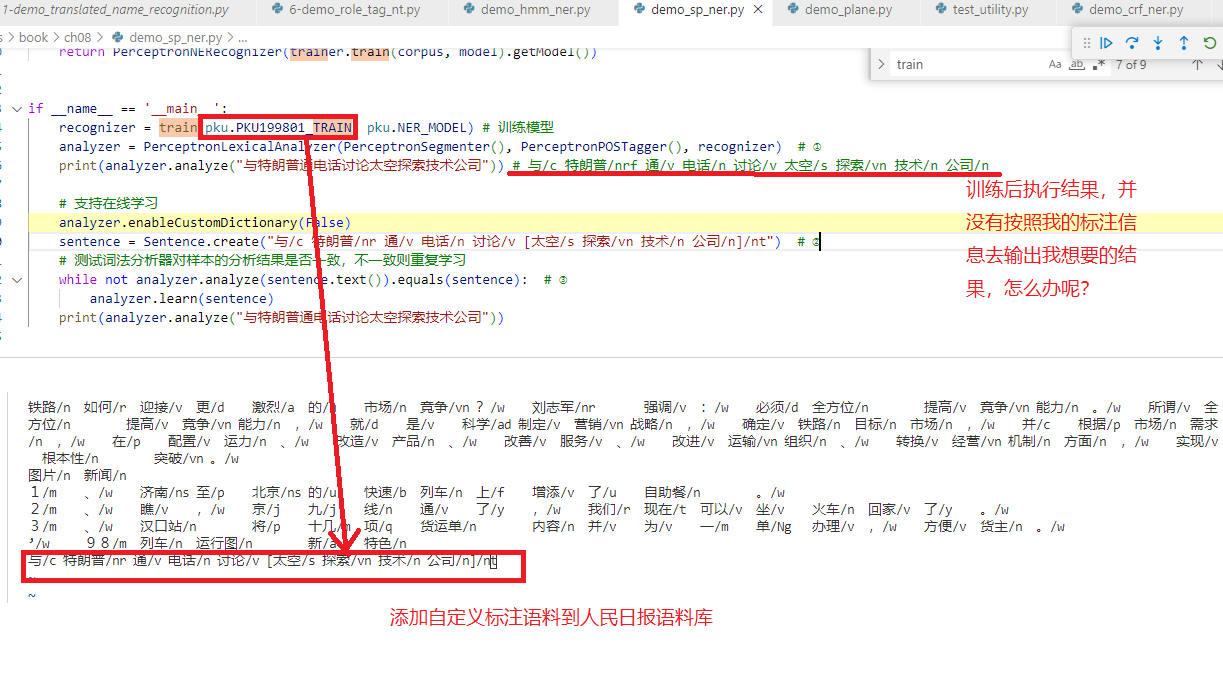
老师好,第8章节的ch08/demo_sp_ner.py, 我把标注好的语料“与/c 特朗普/nr 通/v 电话/n 讨论/v [太空/s 探索/vn 技术/n 公司/n]/nt” 添加到人民日报语料中去,重新train,执行print(analyzer.analyze(“与特朗普通电话讨论太空探索技术公司”)),运行结果还是没有按照我的格式输出,请问为什么语料中有的标注信息没有正确输出呢,应该多输入几行这个标注,还是应该怎么办呢?
1 Like
当数据集本身线性不可分时,感知机算法不保证训练集中的任何样本会被正确分类。你可以oversample一个样本来强调它的重要性。
谢谢老师,我想1. 要么把这个样本在训练语料中多重复几次,也就是您说的oversample, 2. 要么通过代码中的在线学习,save,下次用直接load就行。但是要save这个analyzer, 再load它,有这方面的代码吗老师,我没有找到呢,谢谢~
第二个参数就是保存路径。
加载:
谢谢老师,以python的形式怎么保存和加载analyzer呢?我知道analyzer里面的三个部分:分词,标注,实体识别是如何保存和加载,因为在线学习是整个analyzer的分析器,怎么用python整体把analyzer进行保存和加载呢?感谢老师。
analyzer不负责保存与加载。