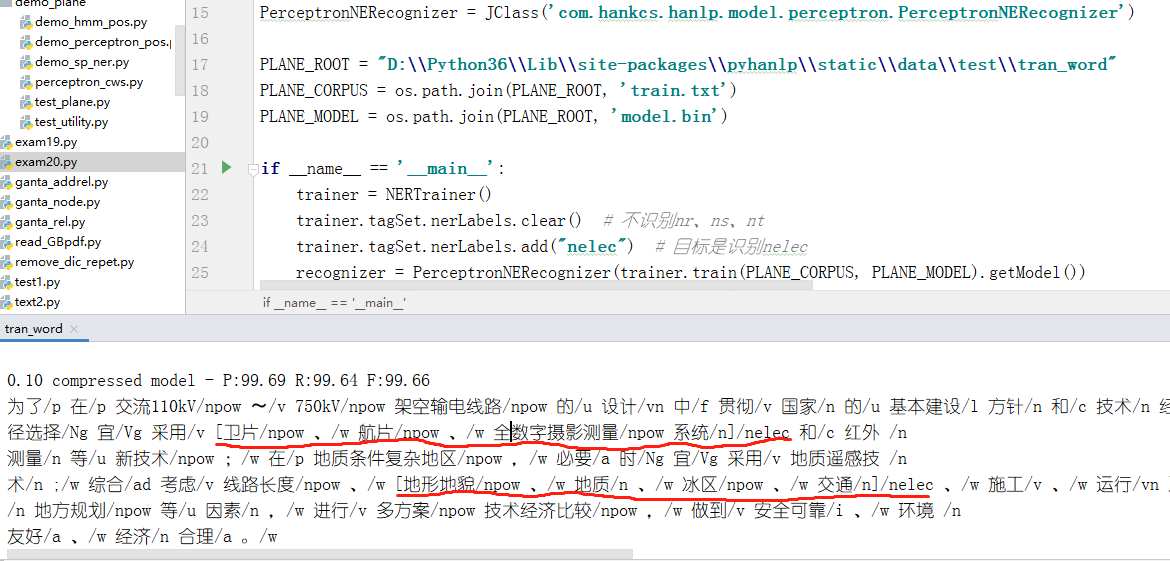
问题描述:您好!我这段时间仿照战斗机的例子,想训练出输电领域命名实体识别的模型。在此之前,我先加了一个自定义词典(大概800行,词性/npow)。然后根据感知机模型(系统自带的)进行分词及词性标注,将一个生语料分词得到一个分词后txt文件,然后用中括号标出边界和词性,
(如:为了/p 在/p [交流110kV/npow 〜/v 750kV/npow]/nelec [架空输电线路/npow 的/u 设计/vn]/nelec 中/f 贯彻/v 国家/n 的/u 基本建设/l 方针/n 和/c 技术/n 经济/n 政策/n ,/w 做到/v 安全可靠/i 、/w 先进/a 适用/a 、/w 经济/n 合理/a 、/w 资源/n 节约/v 、/w 环境友好/nz ,/w 制定/v 本/r 规范/n 。)
最后得到一个熟语料tran.txt(比较小81KB,而你的战斗机的tran.txt有1179KB)。
然后运行训练程序,
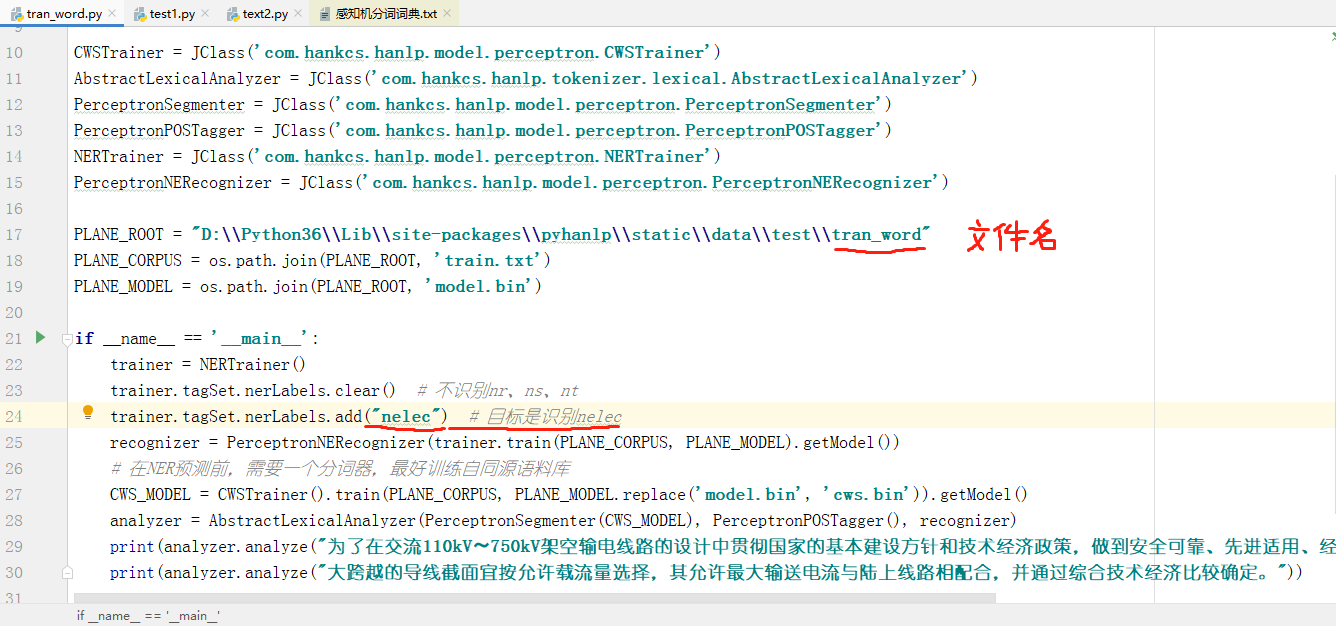
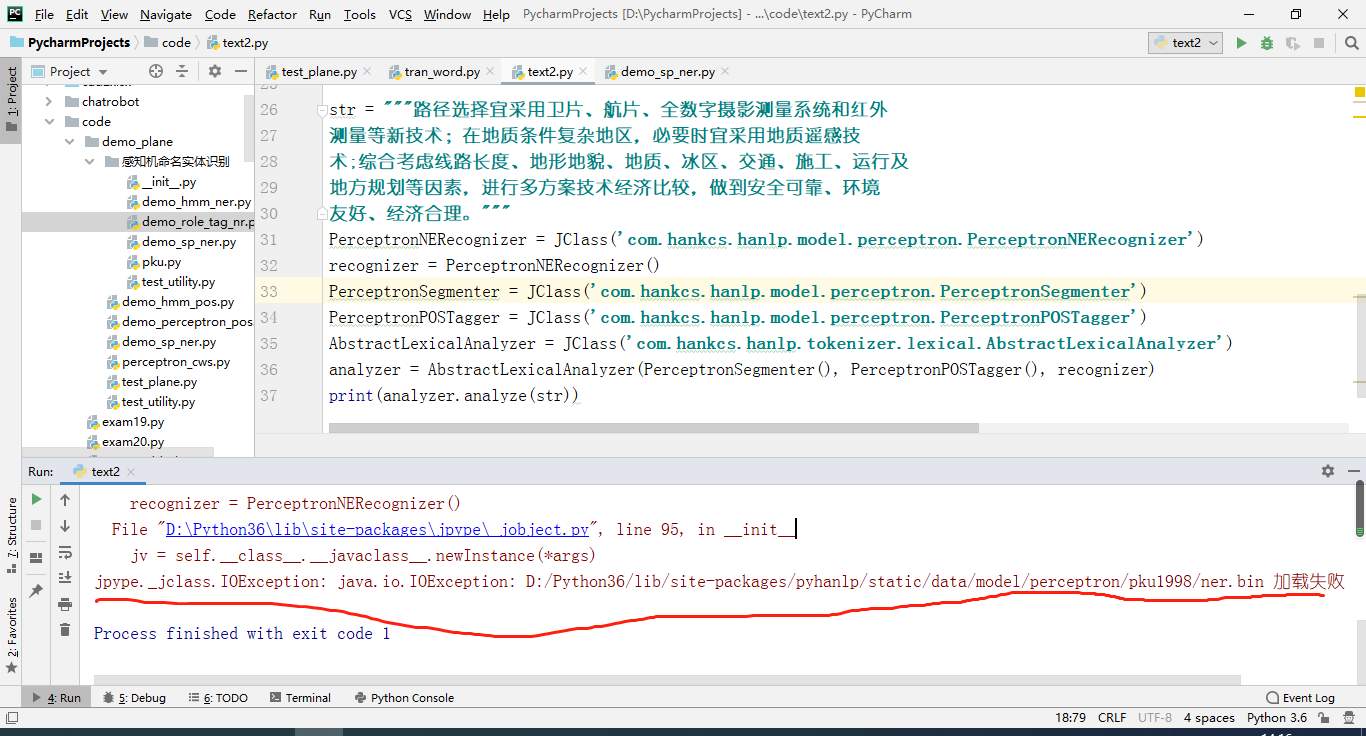
运行结果如下:

结果并没有出现我想要识别的/nelec:为了/p 在/p [交流110kV/npow 〜/v 750kV/npow]/nelec [架空输电线路/npow 的/u 设计/vn]/nelec 中/f 贯彻/v 国家/n 的/u 基本建设/l 方针/n…
我想得到一点建议。
我出现这个无法识别的问题,我有几个猜测:是不是语料的量级太小?是不是需要在NER预测前,需要训练一个分词器,最好训练自同源语料库?是不是我的自定义词典会有影响?
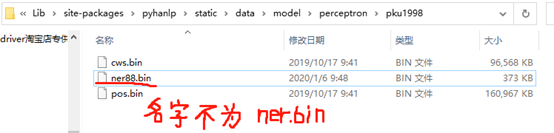
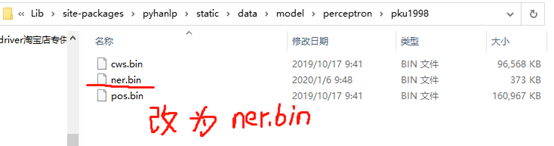
最后我想问一下DS_STORE文件可以通用吗,我加了该文件,战斗机的例子就能识别新的战斗机型号,去掉了战斗机例子中的.DS_Store文件就无法正确识别新型号。

先谢谢大佬抽空看完了。。。