
大家好,本人小白一个,最近研究一个课题,用HanLP分词、词性标注、依存句法分析/语义依存分析识别发票中开具的货物劳务名称,这是个很有落地应用价值的课题,自从有发票以来都没有很好的解决,在Tensorflow CPU版上已经跑通了,只是速度比较慢。然后我给电脑装了GeForce GTX 1060 6G的显卡,win10+CUDA10.1+cuDNN7.6+tensorflow-gpu-2.3.0也驱动起来了,跑没有引用自定义词库的分词、词性标注、依存句法分析/语义依存分析识别是可以的,速度快了约10倍,但引用自定义词库涉及到CPU部分的split_sents()与merge_parts()就不行,详见HanLP2.0实例https://github.com/hankcs/HanLP/blob/doc-zh/tests/demo/zh/demo_cws_trie.py 。我阅读了本坛的贴子 https://bbs.hankcs.com/t/hanlp2-0-ner/1090, @illusions 说他测试过是不支持GPU的,请问各位有解决的办法了么?谢谢!
我尝试过多进程的例子,见https://github.com/hankcs/HanLP/blob/doc-zh/tests/demo/zh/demo_multiprocess.py,不过我的机器内存不够,只有8G,开不了多个进程去跑完整的pipline(单跑分词可以开2个进程)。
这个pipline可以用GPU并发:
parser = hanlp.pipeline()
.append(tokenizer, output_key=‘tokens’)
.append(tagger,input_key=‘tokens’, output_key=‘postags’)
.append(syntactic_parser, input_key=(‘tokens’,‘postags’), output_key=‘syntactic_dependencies’)
这个用自定义词库的就不行:
parser2 = hanlp.pipeline()
.append(split_sents, output_key=(‘parts’, ‘offsets’, ‘words’), trie=trie)
.append(tokenizer, input_key=‘parts’, output_key=‘tokens’)
.append(tagger,input_key=‘tokens’, output_key=‘postags’)
.append(merge_parts, input_key=(‘tokens’, ‘postags’, ‘offsets’, ‘words’), output_key=‘merged’)
.append(syntactic_parser, input_key=‘merged’, output_key=‘syntactic_dependencies’)
盼复,谢谢!
因为发票中有大量一般人日常生活中不常见的专有名词,比如药名等,所以各种NLP语料库中出现的频率不高,导致分词中还是有10%~20%的货物劳务名称不能有效分词,专用自定义词库是比较好的解决办法。如果HanLP用自定义词库时不能通过GPU并行,也许可以用其它的办法绕过去,比如:
1、先通过并发进程调用split_sents()函数把货物劳务名称划分为有自定义词(10~20%)与无自定义词的两部分(80~90%)。
2、无自定义词的部分直接用pipline通过GPU并行处理。
3、有自定义词的部分单线程串行处理。
这样应该也可以加快处理速度。目前在我的台式机上,串行的话大约5条/秒,GPU并行的话大约快10倍。发票的数据量非常大,全国每年数以十亿计。准确识别发票上的货物劳务名称是税收大数据微观分析,如产业链、交易链等分析的基础,所以是很有实用价值的。
有兴趣的话可以看看我发在美篇上的两篇课题研究文章,HanLP正好符合我解决问题的需要。准确率超过95%,效果非常好。
HanLP实现发票货物劳务名称识别
https://www.meipian8.cn/370gvt3m?share_depth=3&user_id=ohbsluMlQdetvNnxURjpDJEDPPfg&sharer_id=ojq1tt5xL274R407dIdSCXQFWH7I&first_share_to=&s_uid=85567411&first_share_uid=ohbsluMlQdetvNnxURjpDJEDPPfg&share_source=timeline
HanLP识别发票货物劳务名称之二 小数据集测试
https://www.meipian8.cn/37b5l33b?share_depth=3&user_id=ohbsluMlQdetvNnxURjpDJEDPPfg&sharer_id=ojq1tt5xL274R407dIdSCXQFWH7I&first_share_to=&s_uid=85567411&first_share_uid=ohbsluMlQdetvNnxURjpDJEDPPfg&share_source=timeline
把输入文本分成包含用户自定义词与不包含自定义词的,前者串行处理,后者并行处理,暂时绕过这个问题。
HanLP识别发票货物劳务名称之三 GPU加速
https://www.meipian5.cn/392u3ehj?share_depth=3&user_id=ohbsluMlQdetvNnxURjpDJEDPPfg&sharer_id=ojq1tt5xL274R407dIdSCXQFWH7I&first_share_to=&s_uid=85567411&first_share_uid=ohbsluMlQdetvNnxURjpDJEDPPfg&share_source=timeline
楼主应该是财会软件公司的吧 这么多发票数据可不好找
我也做了一年多的发票名称的处理了 这一块确实很难
拿货物名称的算法后续来做虚开 商贸企业的容易做一些 工业制造的还是很艰难
我是税务局里研究大数据的。
这是个非常大的误解,这两个函数的确只能处理单个句子,但他们本来就是教学用的代码,抛砖引玉启发用户思维用的。
既然是教学代码,你首先要理解它们的作用:
理解之后,我再提两种思路,继续抛砖引玉:
- 蠢办法,在自定义词典中加入一个特殊的词语叫
#给我断句#,再写一个pipeline函数叫merge_sents放到split_sents之前,在该函数中把你要处理的句子链表拼接一下return "#给我断句#".join(sents),也就是输出一整个长句子。这个长句子进入下级管道split_sents,会被拆分为多个片段,有的片段是被自定义词语导致的,有的是因为#给我断句#导致的,就算没有自定义词语,你也将得到多个片段,这些片段形成batch不就能并行分词了吗?分完之后是一整个长句子,你再写一级管道,利用#给我断句#拆分链表,不就得到分完词的句子列表了吗?这样接下来的句法分析等管道不就能够并行了吗? - 如果你觉得上述办法蠢,你当然可以自己写逻辑,记录每个片段从属于哪个句子,在分词之后再把它们拼接回来,不就行了吗?
如同我在示例中的留言一样,“聪明人知道自己加”。HanLP的设计灵活程度非常大,请发挥想象力和创造力,机会是留给聪明人的。
有道理,应该行得通。
不过有个小小的疑问,我有个印象,在其他NLP中,分词与词性标注是与上下文有关的,如果拼成一个长句子,会不会有影响?我对NLP、HanLP、深度学习的了解都不多,现在是想先拿来用,先解决问题。
你没明白上述流程,拆分长句子在前,词性标注在后,完全不受影响。再仔细思考一下吧
按@hankcs的方案搞定,用户自定义词典下也可以用GPU并发流水线,谢谢hankcs!  。
。
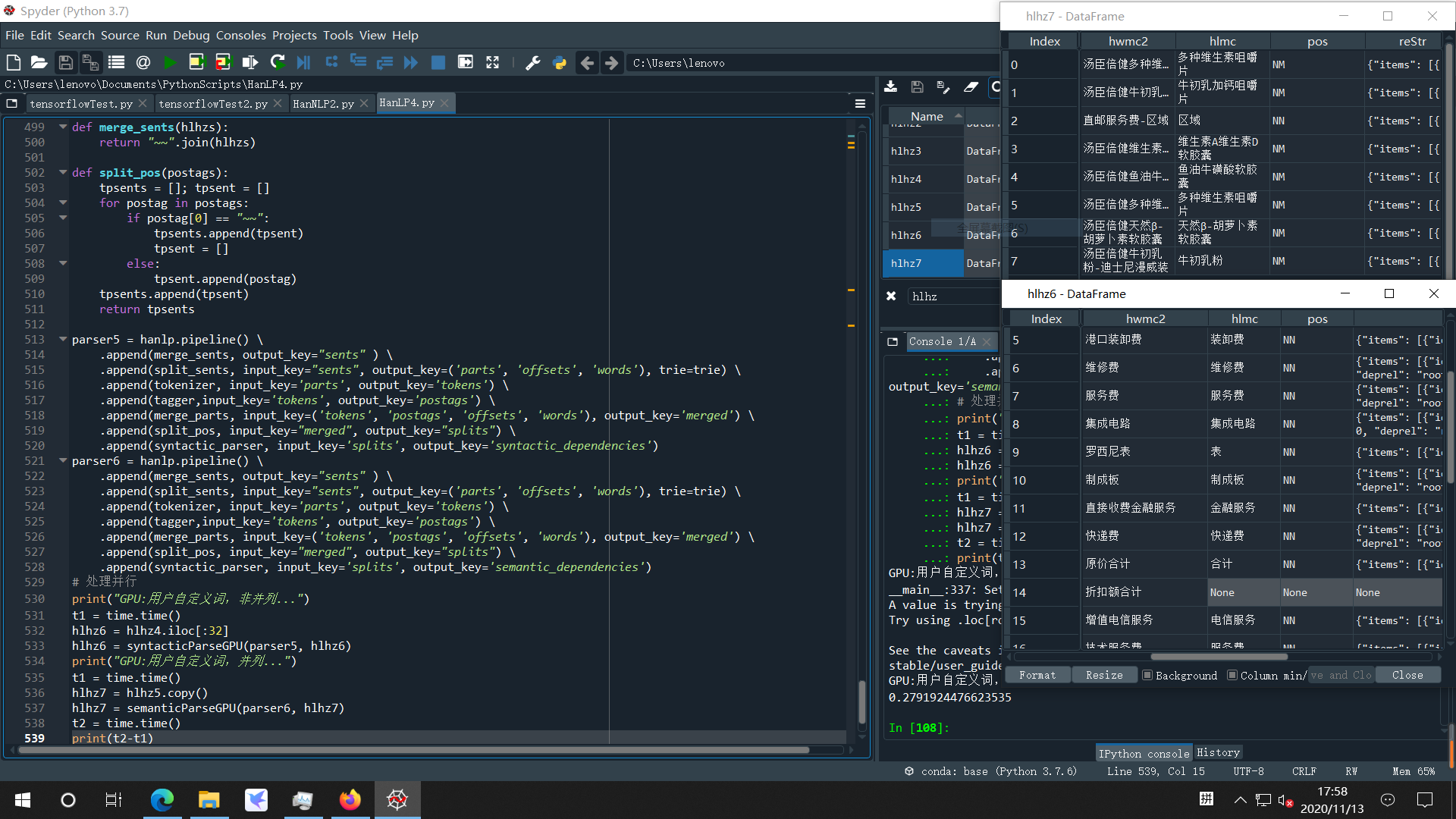
不过还有个自定义词典的小问题,第44条“增值电信服务费”引起了错误,可能是因为词典中有“电信服务”与“服务费”两个词,之前在CPU单线程时也碰到过这种情况。
代码如下:
def merge_sents(hlhzs):
return “~~”.join(hlhzs)
def split_pos(postags):
tpsents = ; tpsent =
for postag in postags:
if postag[0] == “~~”:
tpsents.append(tpsent)
tpsent =
else:
tpsent.append(postag)
tpsents.append(tpsent)
return tpsents
parser5 = hanlp.pipeline()
.append(merge_sents, output_key=“sents” )
.append(split_sents, input_key=“sents”, output_key=(‘parts’, ‘offsets’, ‘words’), trie=trie)
.append(tokenizer, input_key=‘parts’, output_key=‘tokens’)
.append(tagger,input_key=‘tokens’, output_key=‘postags’)
.append(merge_parts, input_key=(‘tokens’, ‘postags’, ‘offsets’, ‘words’), output_key=‘merged’)
.append(split_pos, input_key=“merged”, output_key=“splits”)
.append(syntactic_parser, input_key=‘splits’, output_key=‘syntactic_dependencies’)
parser6 = hanlp.pipeline()
.append(merge_sents, output_key=“sents” )
.append(split_sents, input_key=“sents”, output_key=(‘parts’, ‘offsets’, ‘words’), trie=trie)
.append(tokenizer, input_key=‘parts’, output_key=‘tokens’)
.append(tagger,input_key=‘tokens’, output_key=‘postags’)
.append(merge_parts, input_key=(‘tokens’, ‘postags’, ‘offsets’, ‘words’), output_key=‘merged’)
.append(split_pos, input_key=“merged”, output_key=“splits”)
.append(syntactic_parser, input_key=‘splits’, output_key=‘semantic_dependencies’)
处理并行
print(“GPU:用户自定义词,非并列…”)
t1 = time.time()
hlhz6 = hlhz4.iloc[:44]
hlhz6 = syntacticParseGPU(parser5, hlhz6)
print(“GPU:用户自定义词,并列…”)
t1 = time.time()
hlhz7 = hlhz5.copy()
hlhz7 = semanticParseGPU(parser6, hlhz7)
t2 = time.time()
print(t2-t1)
输出错误:
hlhz6 = syntacticParseGPU(parser5, hlhz6)
Traceback (most recent call last):
File “”, line 1, in
hlhz6 = syntacticParseGPU(parser5, hlhz6)
File “”, line 315, in syntacticParseGPU
res = syn_parser(list(hlhz[“hwmc2”]))
File “d:\Anaconda3\lib\site-packages\hanlp-2.0.0a61-py3.7.egg\hanlp\components\pipeline.py”, line 97, in call
doc = component(doc)
File “d:\Anaconda3\lib\site-packages\hanlp-2.0.0a61-py3.7.egg\hanlp\common\component.py”, line 51, in call
return self.predict(data, **kwargs)
File “d:\Anaconda3\lib\site-packages\hanlp-2.0.0a61-py3.7.egg\hanlp\components\pipeline.py”, line 50, in predict
output = self.component(input, **kwargs)
File “d:\Anaconda3\lib\site-packages\hanlp-2.0.0a61-py3.7.egg\hanlp\common\component.py”, line 51, in call
return self.predict(data, **kwargs)
File “d:\Anaconda3\lib\site-packages\hanlp-2.0.0a61-py3.7.egg\hanlp\components\taggers\rnn_tagger.py”, line 47, in predict
return super().predict(sents, batch_size)
File “d:\Anaconda3\lib\site-packages\hanlp-2.0.0a61-py3.7.egg\hanlp\common\component.py”, line 461, in predict
for output in self.predict_batch(batch, inputs=inputs, **kwargs):
File “d:\Anaconda3\lib\site-packages\hanlp-2.0.0a61-py3.7.egg\hanlp\common\component.py”, line 471, in predict_batch
Y = self.model.predict_on_batch(X)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py”, line 1788, in predict_on_batch
outputs = predict_function(iterator)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py”, line 1462, in predict_function
return step_function(self, iterator)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py”, line 1452, in step_function
outputs = model.distribute_strategy.run(run_step, args=(data,))
File “d:\Anaconda3\lib\site-packages\tensorflow\python\distribute\distribute_lib.py”, line 1211, in run
return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\distribute\distribute_lib.py”, line 2585, in call_for_each_replica
return self._call_for_each_replica(fn, args, kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\distribute\distribute_lib.py”, line 2945, in _call_for_each_replica
return fn(*args, **kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\autograph\impl\api.py”, line 275, in wrapper
return func(*args, **kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py”, line 1445, in run_step
outputs = model.predict_step(data)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\training.py”, line 1418, in predict_step
return self(x, training=False)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\base_layer.py”, line 985, in call
outputs = call_fn(inputs, *args, **kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\sequential.py”, line 372, in call
return super(Sequential, self).call(inputs, training=training, mask=mask)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\functional.py”, line 386, in call
inputs, training=training, mask=mask)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\functional.py”, line 508, in _run_internal_graph
outputs = node.layer(*args, **kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\layers\wrappers.py”, line 530, in call
return super(Bidirectional, self).call(inputs, **kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\base_layer.py”, line 985, in call
outputs = call_fn(inputs, *args, **kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\layers\wrappers.py”, line 644, in call
initial_state=forward_state, **kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\layers\recurrent.py”, line 659, in call
return super(RNN, self).call(inputs, **kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\engine\base_layer.py”, line 985, in call
outputs = call_fn(inputs, *args, **kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\layers\recurrent_v2.py”, line 1177, in call
**gpu_lstm_kwargs)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\keras\layers\recurrent_v2.py”, line 1409, in gpu_lstm
time_major=time_major)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\ops\gen_cudnn_rnn_ops.py”, line 1918, in cudnn_rnnv3
is_training=is_training, time_major=time_major, name=name, ctx=_ctx)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\ops\gen_cudnn_rnn_ops.py”, line 2012, in cudnn_rnnv3_eager_fallback
attrs=_attrs, ctx=ctx, name=name)
File “d:\Anaconda3\lib\site-packages\tensorflow\python\eager\execute.py”, line 60, in quick_execute
inputs, attrs, num_outputs)
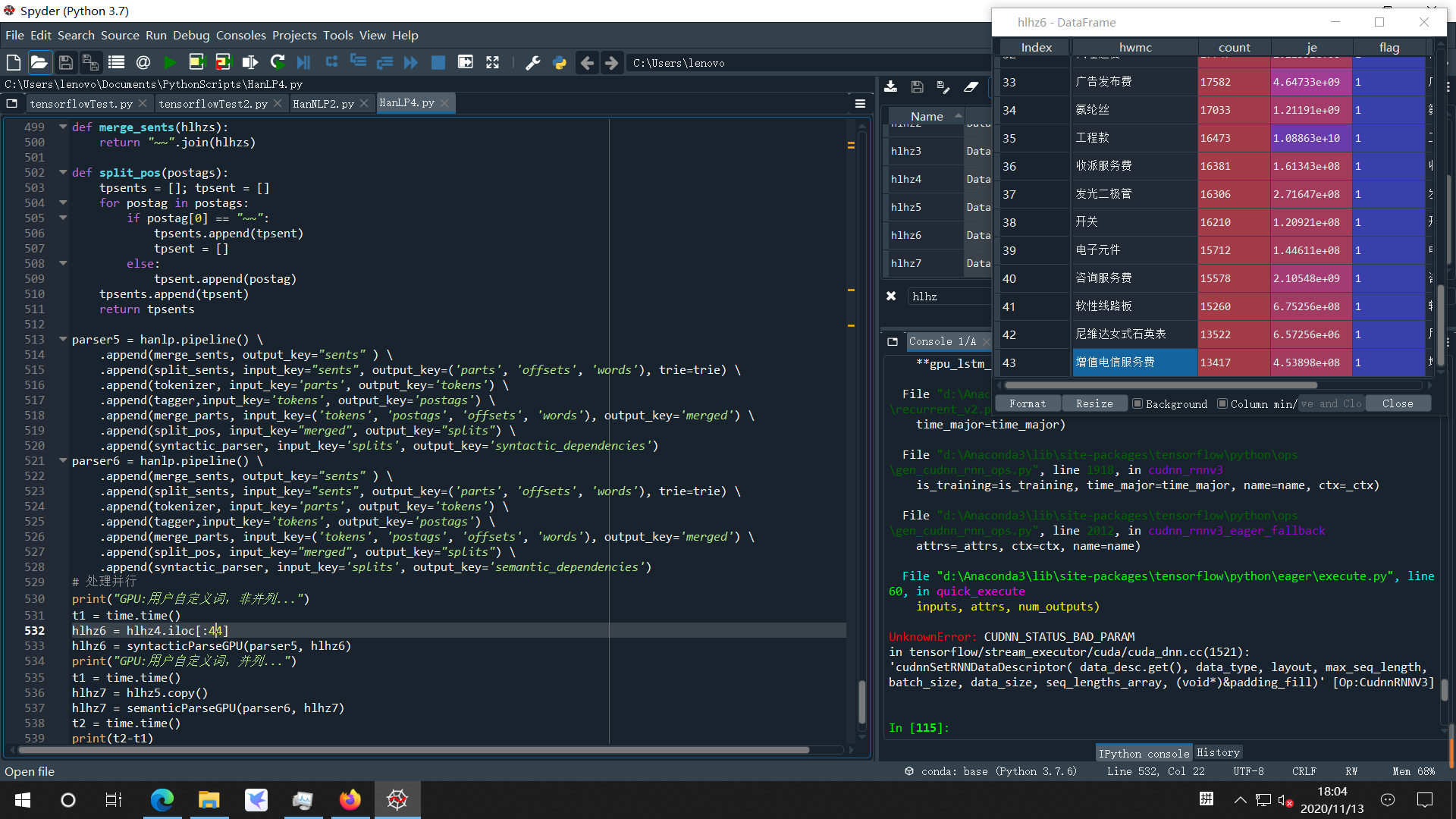
UnknownError: CUDNN_STATUS_BAD_PARAM
in tensorflow/stream_executor/cuda/cuda_dnn.cc(1521): ‘cudnnSetRNNDataDescriptor( data_desc.get(), data_type, layout, max_seq_length, batch_size, data_size, seq_lengths_array, (void*)&padding_fill)’ [Op:CudnnRNNV3]
你的tagger应该放到split_pos之后,于是split_pos就不用拆分词性了。
你可以把tagger换成print函数,打印一下接受的参数,看看是否合法。
在上面第一幅图中,batch_size=32,即不包含索引号为43的第44条时,程序正常执行,结果也正确,我用该条之后的一组数据测试也O.K.,所以整体框架应该是正确的。
我看了split_sents的源码,理解为自定义词典的(词,值)tuple中词是字典的键值key,值是业务逻辑value,因此在这个应用中我把它定义为词性。所以tokenizer、tagger只对split_sents剩余的部分parts执行,merge_parts合并的话就包括词与词性了,它输出的结果是一个包含了句子分隔符tuple("~~",“W”)的tuple list,然后用split_pos分割为二维列表,传入syntactic_parser并行执行。因此我根据你的注解稍微修改了一下merge_parts函数,前面没有说明。
def split_sents(text: str, trie: Trie):
words = trie.parse_longest(text)
sents =
pre_start = 0
offsets =
for word, value, start, end in words:
if pre_start != start:
sents.append(text[pre_start: start])
offsets.append(pre_start)
pre_start = end
if pre_start != len(text):
sents.append(text[pre_start:])
offsets.append(pre_start)
return sents, offsets, words
def merge_parts(tokens, postags, offsets, words):
tps =
for i in range(len(tokens)):
tps2 = [(token, postag) for (token, postag) in zip(tokens[i], postags[i])]
tps.append(tps2)
#items = [(i, p) for (i, p) in zip(offsets, tokens)]
items = [(i, ts) for (i, ts) in zip(offsets, tps)]
# items += [(start, [word]) for (word, value, start, end) in words]
# In case you need the tag, use the following line instead
items += [(start, [(word, value)]) for (word, value, start, end) in words]
return [each for x in sorted(items) for each in x[1]]
这个是你例子中原来的函数:
def merge_parts(parts, offsets, words):
items = [(i, p) for (i, p) in zip(offsets, parts)]
items += [(start, [word]) for (word, value, start, end) in words]
# In case you need the tag, use the following line instead
# items += [(start, [(word, value)]) for (word, value, start, end) in words]
return [each for x in sorted(items) for each in x[1]]
第44条“增值电信服务费”引起了错误,可能是因为词典中有“电信服务”与“服务费”两个词,这一条的分词有几种可能?Python错误堆栈的输出好像没有java准确,因为之前在CPU单线程时也碰到过这种情况,或者是对merge_part函数修改引起的问题?我对NLP及Trie树,甚至Python的了解还不够多,去年12月才开始接触Python,所以说自己是小白。 
你得先学学markdown。请提供可运行可复现的代码,否则无法排查问题。
应该是 split_sents()函数在处理有多种相互重叠的分词情况下引起的问题,自定义词典的定义导致这种情况发生,修改该函数后解决了问题,测试通过。
import hanlp
from hanlp.common.trie import Trie
import time
# 原自定义词分割函数
def split_sents(text: str, trie: Trie):
words = trie.parse_longest(text)
print(words)
sents = []
pre_start = 0
offsets = []
for word, value, start, end in words:
if pre_start != start:
sents.append(text[pre_start: start])
offsets.append(pre_start)
pre_start = end
if pre_start != len(text):
sents.append(text[pre_start:])
offsets.append(pre_start)
return sents, offsets, words
# 原合并函数
# def merge_parts(parts, offsets, words):
# items = [(i, p) for (i, p) in zip(offsets, parts)]
# items += [(start, [word]) for (word, value, start, end) in words]
# # In case you need the tag, use the following line instead
# # items += [(start, [(word, value)]) for (word, value, start, end) in words]
# return [each for x in sorted(items) for each in x[1]]
# 合并函数
def merge_parts(tokens, postags, offsets, words):
tps = []
for i in range(len(tokens)):
tps2 = [(token, postag) for (token, postag) in zip(tokens[i], postags[i])]
tps.append(tps2)
#items = [(i, p) for (i, p) in zip(offsets, tokens)]
items = [(i, ts) for (i, ts) in zip(offsets, tps)]
# items += [(start, [word]) for (word, value, start, end) in words]
# In case you need the tag, use the following line instead
items += [(start, [(word, value)]) for (word, value, start, end) in words]
return [each for x in sorted(items) for each in x[1]]
t1 = time.time()
# 装入分词模型
print("装入HanLP分词、词性标注、依存句法分析、语义依存分析模型...")
tokenizer = hanlp.load('LARGE_ALBERT_BASE')
# 装入词性标注模型
tagger = hanlp.load(hanlp.pretrained.pos.CTB5_POS_RNN_FASTTEXT_ZH)
# 装入依存句法分析模型
syntactic_parser = hanlp.load(hanlp.pretrained.dep.CTB7_BIAFFINE_DEP_ZH)
# 装入语义依存分析模型
semantic_parser = hanlp.load(hanlp.pretrained.sdp.SEMEVAL16_NEWS_BIAFFINE_ZH)
# 装入用户自定义词典
trie = Trie()
trie.update({'电信服务': 'NN', '服务费': 'NN',"合计": "NN",'~~': 'W'})
t2 = time.time()
print("模型已装入...", t2-t1)
parser = hanlp.pipeline() \
.append(split_sents, output_key=('parts', 'offsets', 'words'), trie=trie) \
.append(tokenizer, input_key='parts', output_key='tokens')
parser2 = hanlp.pipeline() \
.append(split_sents, output_key=('parts', 'offsets', 'words'), trie=trie) \
.append(tokenizer, input_key='parts', output_key='tokens') \
.append(tagger,input_key='tokens', output_key='postags')
# 测试文本
text = "增值电信服务费"
# 执行出错
res2 = parser2(text)
# 执行通过,所以问题在tagger的执行
res = parser(text)
# 打印分词的结果
print(res.tokens) # [['增值'], []]
print(res.words) # [('电信服务', 'NN', 2, 6), ('服务费', 'NN', 4, 7)]
# 单独执行每个token的词性标注都可以
print(tagger(res.tokens[0])) # ['NN']
print(tagger(res.tokens[1])) # []
# 一起执行就有错,应该上传入的二维列表中有空的子列表,
# 但上一行print(tagger(res.tokens[1]))对空的列表执行tagger是可以的。
print(tagger(res.tokens))
#所以原因应该是split_sents()中取自定义词输出了空串,
#在这种存在多种匹配分词可能的情况下,text[pre_start: start]出现了pre_start>start的情况
print(res.parts) # ['增值', '']
# 更改分割函数,检查一下取词是否输出空串, 抛弃trie树返回的结果中与前一个词有重叠的词
def split_sents2(text: str, trie: Trie):
words = trie.parse_longest(text)
#print(words)
sents = []
words2 = []
pre_start = 0
offsets = []
for word, value, start, end in words:
# print(word, value, start, end, pre_start, start)
if pre_start != start:
word2 = text[pre_start: start]
if len(word2)>0:
# print(word2)
sents.append(text[pre_start: start])
words2.append(tuple([word,value,start,end]))
offsets.append(pre_start)
pre_start = end
else:
print("自定义词有重叠,跳过:",word,value,start,end)
else:
print("自定义词首尾相接:",pre_start, start)
words2.append(tuple([word,value,start,end]))
pre_start = end
if pre_start != len(text):
sents.append(text[pre_start:])
offsets.append(pre_start)
return sents, offsets, words2
def merge_sents(hlhzs):
return "~~".join(hlhzs)
def split_pos(postags):
tpsents = []; tpsent = []
for postag in postags:
if postag[0] == "~~":
tpsents.append(tpsent)
tpsent = []
else:
tpsent.append(postag)
tpsents.append(tpsent)
return tpsents
# 测试GPU并行
text = ["原价合计","增值电信服务费","折扣额合计"]
# 测试自定义词分割,通过
res = split_sents2(merge_sents(text), trie)
print(res)
# 分词及词性标注
parser3 = hanlp.pipeline() \
.append(merge_sents, output_key="sents" ) \
.append(split_sents2, input_key="sents", output_key=('parts', 'offsets', 'words'), trie=trie) \
.append(tokenizer, input_key='parts', output_key='tokens') \
.append(tagger,input_key='tokens', output_key='postags') \
.append(merge_parts, input_key=('tokens', 'postags', 'offsets', 'words'), output_key='merged')
# 执行通过
res3 = parser3(text)
print(res3)
# 依存句法分析
parser4 = hanlp.pipeline() \
.append(merge_sents, output_key="sents" ) \
.append(split_sents2, input_key="sents", output_key=('parts', 'offsets', 'words'), trie=trie) \
.append(tokenizer, input_key='parts', output_key='tokens') \
.append(tagger,input_key='tokens', output_key='postags') \
.append(merge_parts, input_key=('tokens', 'postags', 'offsets', 'words'), output_key='merged') \
.append(split_pos, input_key="merged", output_key="splits") \
.append(syntactic_parser, input_key='splits', output_key='syntactic_dependencies')
# 执行通过
res4 = parser4(text)
print(res4)
# 语义依存分析
parser5 = hanlp.pipeline() \
.append(merge_sents, output_key="sents" ) \
.append(split_sents2, input_key="sents", output_key=('parts', 'offsets', 'words'), trie=trie) \
.append(tokenizer, input_key='parts', output_key='tokens') \
.append(tagger,input_key='tokens', output_key='postags') \
.append(merge_parts, input_key=('tokens', 'postags', 'offsets', 'words'), output_key='merged') \
.append(split_pos, input_key="merged", output_key="splits") \
.append(semantic_parser, input_key='splits', output_key='semantic_dependencies')
# 执行通过
res5 = parser5(text)
print(res5)
trie.parse_longest曾经有一个bug,请升级最新版:
split_sents()改成split_sents2()函数后,解决了自定义词典中词条不能互相包含和文本中出现多种互相重叠分词可能性冲突的问题,自定义词典就没有什么限制了。按split_sents2()的规则,自定义词会选择先匹配并且最长匹配的一个, trie.parse_longest()函数已经实现了这一点。因此,当出现一些较长的专有名词不能正确分词时,往自定义词典末尾直接添加即可。比如下面这个例子:
# 装入用户自定义词典
trie = Trie()
trie.update({'电信服务': 'NN', '服务费': 'NN',"增值电信服务费":"NN","合计": "NN",'~~': 'W'})
text = "增值电信服务费"
res = split_sents2(text, trie)
print(res)
输出如下:
res = split_sents2(text, trie)
[(‘增值电信服务费’, ‘NN’, 0, 7), (‘电信服务’, ‘NN’, 2, 6), (‘服务费’, ‘NN’, 4, 7)]
自定义词首尾相接: 0 0
自定义词有重叠,跳过: 电信服务 NN 2 6
自定义词有重叠,跳过: 服务费 NN 4 7
print(res)
(, , [(‘增值电信服务费’, ‘NN’, 0, 7)])
trie.parse_longest()函数返回了3个匹配的词,先出现的最长匹配排在前面,split_sents2()函数跳过了后面两个有重叠的候选词,这正是我想要的结果。
# 更改分割函数,检查一下取词是否输出空串, 抛弃trie树返回的结果中与前一个词有重叠的词
def split_sents2(text: str, trie: Trie):
words = trie.parse_longest(text)
print(words)
sents = []
words2 = []
pre_start = 0
offsets = []
for word, value, start, end in words:
# print(word, value, start, end, pre_start, start)
if pre_start != start:
word2 = text[pre_start: start]
if len(word2)>0:
# print(word2)
sents.append(word2)
words2.append(tuple([word,value,start,end]))
offsets.append(pre_start)
pre_start = end
else:
print("自定义词有重叠,跳过:",word,value,start,end)
else:
print("自定义词首尾相接:",pre_start, start)
words2.append(tuple([word,value,start,end]))
pre_start = end
if pre_start != len(text):
sents.append(text[pre_start:])
offsets.append(pre_start)
return sents, offsets, words2
# 自定义函数,再合并自定义分词及词性标注,剩余部分的词性分词、词性标注
def merge_parts(tokens, postags, offsets, words):
tps = []
for i in range(len(tokens)):
tps2 = [(token, postag) for (token, postag) in zip(tokens[i], postags[i])]
tps.append(tps2)
items = [(i, ts) for (i, ts) in zip(offsets, tps)]
items += [(start, [(word, value)]) for (word, value, start, end) in words]
return [each for x in sorted(items) for each in x[1]]
def merge_sents(hlhzs):
return "~~".join(hlhzs)
def split_pos(postags):
tpsents = []; tpsent = []
for postag in postags:
if postag[0] == "~~":
tpsents.append(tpsent)
tpsent = []
else:
tpsent.append(postag)
tpsents.append(tpsent)
return tpsents
准确识别货物劳务名称后,可以用igraph重建交易网络,尝试用igraph对交易网络建模与分析,你可以参考一下我的几篇文章:
这第一步很困难。后续我们也做了各种下游应用,包括团伙分析、产业链、虚开检测等等,但每一个应用都无法用得很省心,这些算法的压力都会给到货物名称识别上面。
而货物名称识别算法的上限并不算太高,根源原因主要来源于货物名称的复杂+编码表本身的不合理。
税收分类代码是为宏观税收分析设计的,只有4200多个,而货物劳务名称有数十至数百万种,并且税收分类代码与货物劳务名称之间没有明确的对应关系,所以它很难用于虚开分析等微观的风险分析,微观分析必须明确交易对象才可以准确执行。
现在我这个方案就是要解决这个基础性的问题,并且建立税收分类代码与货物劳务名称之间明确的对应关系,贯通宏观与微观。通过用户自定义词典+分词+词性标注+句法/语义分析,结合货物劳务名称名词短语的特征建立其内部结构,再通过广度优先搜索算法提取识别,效果非常好,准确率超过95%,应该可以达到98%~99%之间。然后可以通过各种分类算法建立税收分类代码与货劳名称的对应关系。
HanLP2.0为这个解决方案提供了关键的支持,我之前也测试过国内5家NLP大厂的产品,都没有完全支持我的需求,最后找到了HanLP才解决了问题,所以非常感谢HanLP的开发团队,尤其是小何博士 @hankcs !如果这个解决方案能落地应用并产生效益,小何博士和HanLP的开发团队作出了重要的贡献。
我相信准确重建完整的交易网络后,很多问题都可以通过交易网络分析得以解决,相关的分析技术已经比较成熟了,后面会深入研究。有兴趣可以看看igraph作者的书《R语言网络数据分析》。
小何博士的书我也买了,后面慢慢学习。